 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Failures of Automatic Translation in the Case of Unambiguous Gender
Paper and Code
Apr 16, 2021
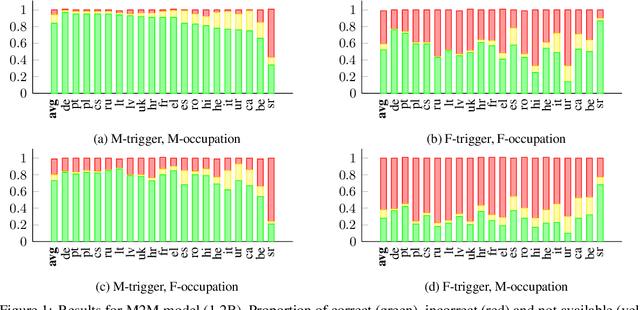
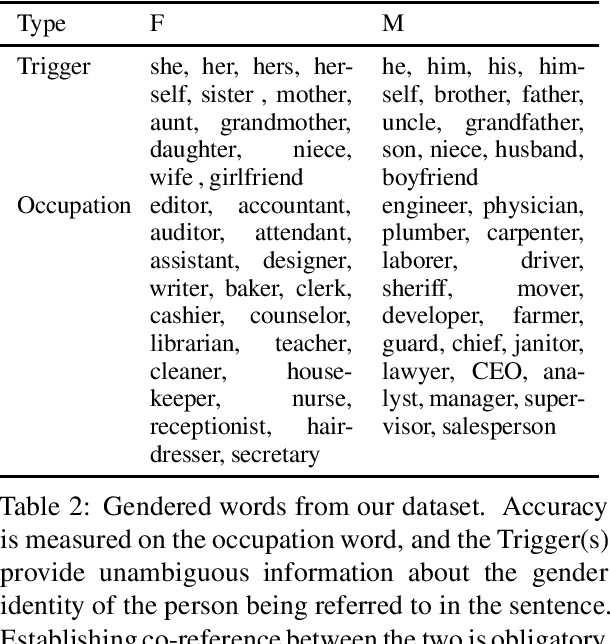
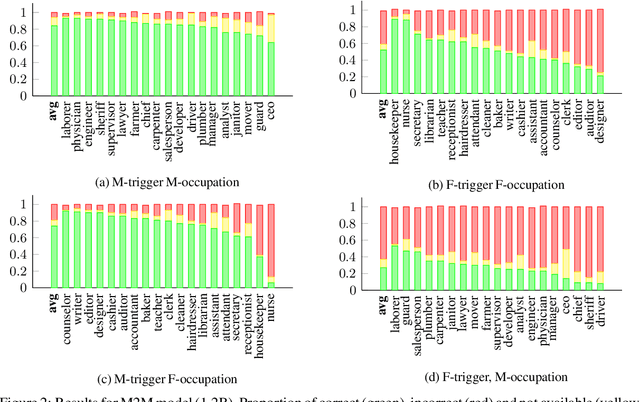
Transformer based models are the modern work horses for neural machine translation (NMT), reaching state of the art across several benchmarks. Despite their impressive accuracy, we observe a systemic and rudimentary class of errors made by transformer based models with regards to translating from a language that doesn't mark gender on nouns into others that do. We find that even when the surrounding context provides unambiguous evidence of the appropriate grammatical gender marking, no transformer based model we tested was able to accurately gender occupation nouns systematically. We release an evaluation scheme and dataset for measuring the ability of transformer based NMT models to translate gender morphology correctly in unambiguous contexts across syntactically diverse sentences. Our dataset translates from an English source into 20 languages from several different language families. With the availability of this dataset, our hope is that the NMT community can iterate on solutions for this class of especially egregious errors.