 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Adversarial Events: A Motion-Aware Point Cloud Framework
Feb 09, 2026Event cameras have been widely adopted in safety-critical domains such as autonomous driving, robotics, and human-computer interaction. A pressing challenge arises from the vulnerability of deep neural networks to adversarial examples, which poses a significant threat to the reliability of event-based systems. Nevertheless, research into adversarial attacks on events is scarce. This is primarily due to the non-differentiable nature of mainstream event representations, which hinders the extension of gradient-based attack methods. In this paper, we propose MA-ADV, a novel \textbf{M}otion-\textbf{A}ware \textbf{Adv}ersarial framework. To the best of our knowledge, this is the first work to generate adversarial events by leveraging point cloud representations. MA-ADV accounts for high-frequency noise in events and employs a diffusion-based approach to smooth perturbations, while fully leveraging the spatial and temporal relationships among events. Finally, MA-ADV identifies the minimal-cost perturbation through a combination of sample-wise Adam optimization, iterative refinement, and binary search. Extensive experimental results validate that MA-ADV ensures a 100\% attack success rate with minimal perturbation cost, and also demonstrate enhanced robustness against defenses, underscoring the critical security challenges facing future event-based perception systems.
Multi-View Learning with Context-Guided Receptance for Image Denoising
May 05, 2025Image denoising is essential in low-level vision applications such as photography and automated driving. Existing methods struggle with distinguishing complex noise patterns in real-world scenes and consume significant computational resources due to reliance on Transformer-based models. In this work, the Context-guided Receptance Weighted Key-Value (\M) model is proposed, combining enhanced multi-view feature integration with efficient sequence modeling. Our approach introduces the Context-guided Token Shift (CTS) paradigm, which effectively captures local spatial dependencies and enhance the model's ability to model real-world noise distributions. Additionally, the Frequency Mix (FMix) module extracting frequency-domain features is designed to isolate noise in high-frequency spectra, and is integrated with spatial representations through a multi-view learning process. To improve computational efficiency, the Bidirectional WKV (BiWKV) mechanism is adopted, enabling full pixel-sequence interaction with linear complexity while overcoming the causal selection constraints. The model is validated on multiple real-world image denoising datasets, outperforming the existing state-of-the-art methods quantitatively and reducing inference time up to 40\%. Qualitative results further demonstrate the ability of our model to restore fine details in various scenes.
OpFlowTalker: Realistic and Natural Talking Face Generation via Optical Flow Guidance
May 23, 2024



Creating realistic, natural, and lip-readable talking face videos remains a formidable challenge. Previous research primarily concentrated on generating and aligning single-frame images while overlooking the smoothness of frame-to-frame transitions and temporal dependencies. This often compromised visual quality and effects in practical settings, particularly when handling complex facial data and audio content, which frequently led to semantically incongruent visual illusions. Specifically, synthesized videos commonly featured disorganized lip movements, making them difficult to understand and recognize. To overcome these limitations, this paper introduces the application of optical flow to guide facial image generation, enhancing inter-frame continuity and semantic consistency. We propose "OpFlowTalker", a novel approach that utilizes predicted optical flow changes from audio inputs rather than direct image predictions. This method smooths image transitions and aligns changes with semantic content. Moreover, it employs a sequence fusion technique to replace the independent generation of single frames, thus preserving contextual information and maintaining temporal coherence. We also developed an optical flow synchronization module that regulates both full-face and lip movements, optimizing visual synthesis by balancing regional dynamics. Furthermore, we introduce a Visual Text Consistency Score (VTCS) that accurately measures lip-readability in synthesized videos. Extensive empirical evidence validates the effectiveness of our approach.
VTQA: Visual Text Question Answering via Entity Alignment and Cross-Media Reasoning
Mar 05, 2023



The ideal form of Visual Question Answering requires understanding, grounding and reasoning in the joint space of vision and language and serves as a proxy for the AI task of scene understanding. However, most existing VQA benchmarks are limited to just picking the answer from a pre-defined set of options and lack attention to text. We present a new challenge with a dataset that contains 23,781 questions based on 10124 image-text pairs. Specifically, the task requires the model to align multimedia representations of the same entity to implement multi-hop reasoning between image and text and finally use natural language to answer the question. The aim of this challenge is to develop and benchmark models that are capable of multimedia entity alignment, multi-step reasoning and open-ended answer generation.
Pyramid Feature Attention Network for Saliency detection
Apr 04, 2019
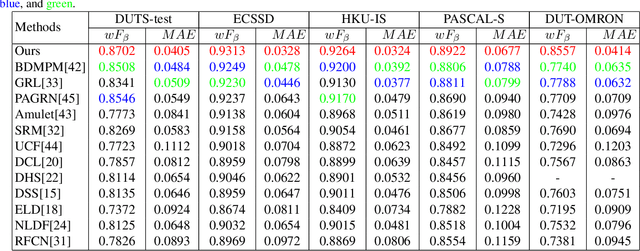
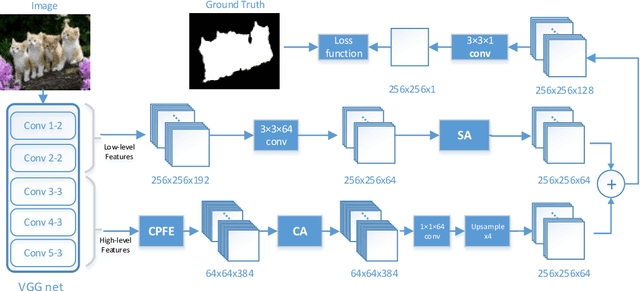
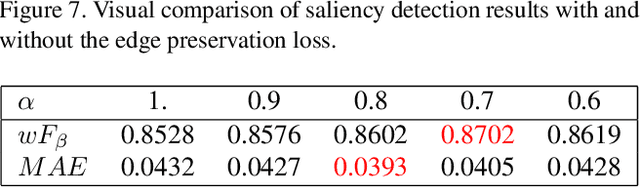
Saliency detection is one of the basic challenges in computer vision. How to extract effective features is a critical point for saliency detection. Recent methods mainly adopt integrating multi-scale convolutional features indiscriminately. However, not all features are useful for saliency detection and some even cause interferences. To solve this problem, we propose Pyramid Feature Attention network to focus on effective high-level context features and low-level spatial structural features. First, we design Context-aware Pyramid Feature Extraction (CPFE) module for multi-scale high-level feature maps to capture rich context features. Second, we adopt channel-wise attention (CA) after CPFE feature maps and spatial attention (SA) after low-level feature maps, then fuse outputs of CA & SA together. Finally, we propose an edge preservation loss to guide network to learn more detailed information in boundary localization. Extensive evaluations on five benchmark datasets demonstrate that the proposed method outperforms the state-of-the-art approaches under different evaluation metrics.
TCDCaps: Visual Tracking via Cascaded Dense Capsules
Feb 26, 2019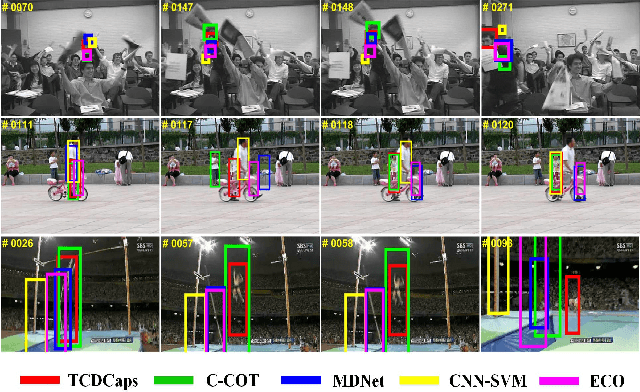
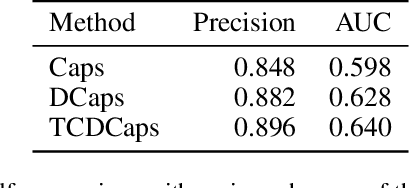
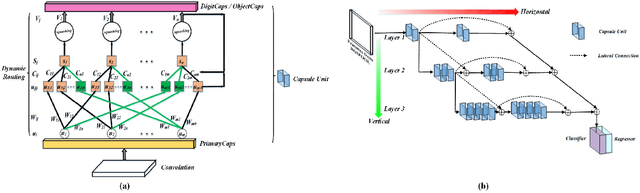

The critical challenge in tracking-by-detection framework is how to avoid drift problem during online learning, where the robust features for a variety of appearance changes are difficult to be learned and a reasonable intersection over union (IoU) threshold that defines the true/false positives is hard to set. This paper presents the TCDCaps method to address the problems above via a cascaded dense capsule architecture. To get robust features, we extend original capsules with dense-connected routing, which are referred as DCaps. Depending on the preservation of part-whole relationships in the Capsule Networks, our dense-connected capsules can capture a variety of appearance variations. In addition, to handle the issue of IoU threshold, a cascaded DCaps model (CDCaps) is proposed to improve the quality of candidates, it consists of sequential DCaps trained with increasing IoU thresholds so as to sequentially improve the quality of candidates. Extensive experiments on 3 popular benchmarks demonstrate the robustness of the proposed TCDCaps.
Saliency Detection via Combining Region-Level and Pixel-Level Predictions with CNNs
Aug 18, 2016
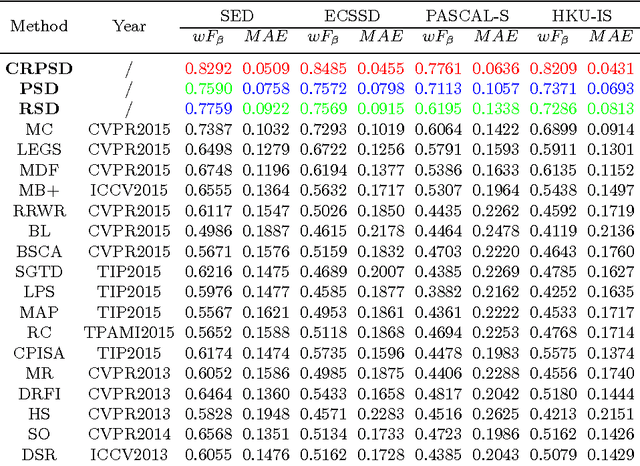
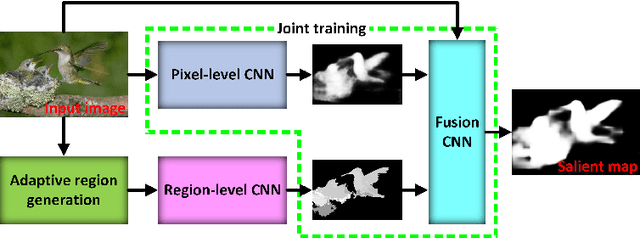
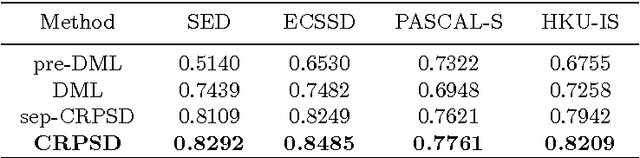
This paper proposes a novel saliency detection method by combining region-level saliency estimation and pixel-level saliency prediction with CNNs (denoted as CRPSD). For pixel-level saliency prediction, a fully convolutional neural network (called pixel-level CNN) is constructed by modifying the VGGNet architecture to perform multi-scale feature learning, based on which an image-to-image prediction is conducted to accomplish the pixel-level saliency detection. For region-level saliency estimation, an adaptive superpixel based region generation technique is first designed to partition an image into regions, based on which the region-level saliency is estimated by using a CNN model (called region-level CNN). The pixel-level and region-level saliencies are fused to form the final salient map by using another CNN (called fusion CNN). And the pixel-level CNN and fusion CNN are jointly learned. Extensive quantitative and qualitative experiments on four public benchmark datasets demonstrate that the proposed method greatly outperforms the state-of-the-art saliency detection approaches.
Deeply-Supervised Recurrent Convolutional Neural Network for Saliency Detection
Aug 18, 2016
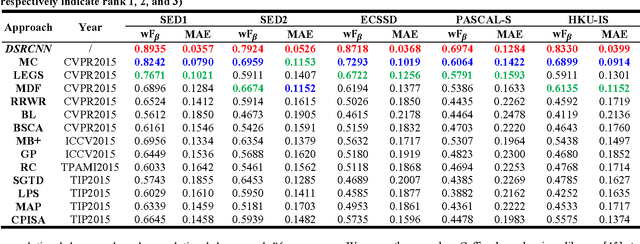
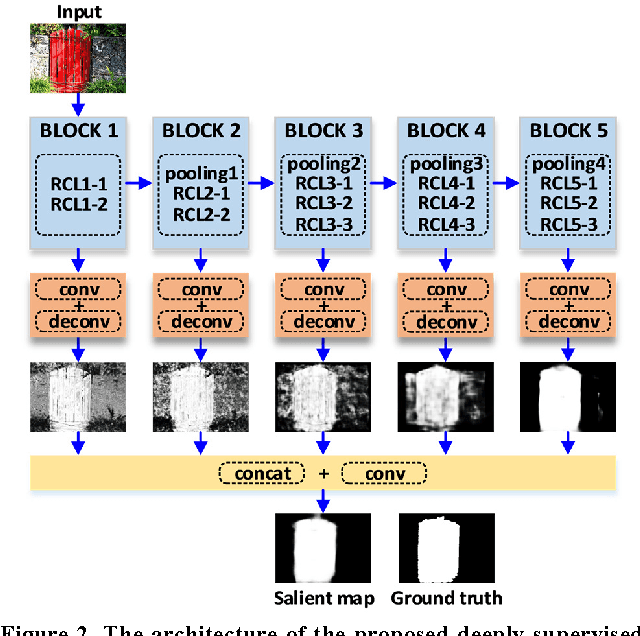
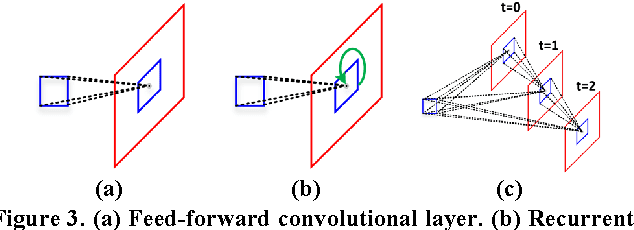
This paper proposes a novel saliency detection method by developing a deeply-supervised recurrent convolutional neural network (DSRCNN), which performs a full image-to-image saliency prediction. For saliency detection, the local, global, and contextual information of salient objects is important to obtain a high quality salient map. To achieve this goal, the DSRCNN is designed based on VGGNet-16. Firstly, the recurrent connections are incorporated into each convolutional layer, which can make the model more powerful for learning the contextual information. Secondly, side-output layers are added to conduct the deeply-supervised operation, which can make the model learn more discriminative and robust features by effecting the intermediate layers. Finally, all of the side-outputs are fused to integrate the local and global information to get the final saliency detection results. Therefore, the DSRCNN combines the advantages of recurrent convolutional neural networks and deeply-supervised nets. The DSRCNN model is tested on five benchmark datasets, and experimental results demonstrate that the proposed method significantly outperforms the state-of-the-art saliency detection approaches on all test datasets.