 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency Detection via Combining Region-Level and Pixel-Level Predictions with CNNs
Paper and Code
Aug 18, 2016
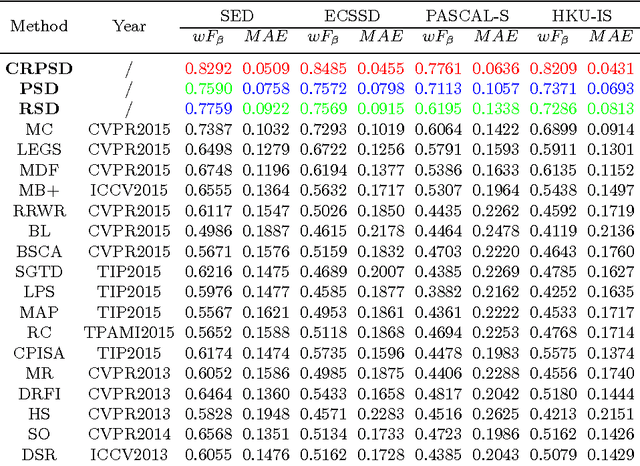
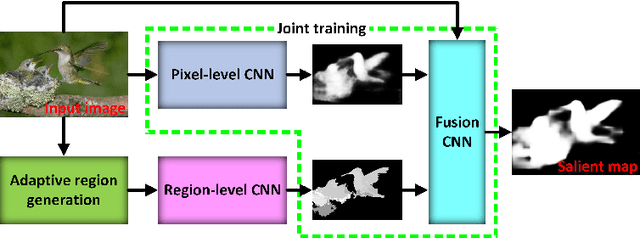
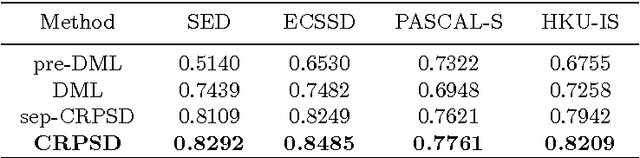
This paper proposes a novel saliency detection method by combining region-level saliency estimation and pixel-level saliency prediction with CNNs (denoted as CRPSD). For pixel-level saliency prediction, a fully convolutional neural network (called pixel-level CNN) is constructed by modifying the VGGNet architecture to perform multi-scale feature learning, based on which an image-to-image prediction is conducted to accomplish the pixel-level saliency detection. For region-level saliency estimation, an adaptive superpixel based region generation technique is first designed to partition an image into regions, based on which the region-level saliency is estimated by using a CNN model (called region-level CNN). The pixel-level and region-level saliencies are fused to form the final salient map by using another CNN (called fusion CNN). And the pixel-level CNN and fusion CNN are jointly learned. Extensive quantitative and qualitative experiments on four public benchmark datasets demonstrate that the proposed method greatly outperforms the state-of-the-art saliency detection approaches.