 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturbative methods for non-parametric instrumental variable
May 29, 2026We introduce a perturbative approach for nonparametric instrumental variable (NPIV) estimation. By drawing inspiration from perturbation theory in physics, we extend standard kernel ridge methods with systematic higher perturbation order corrections that significantly improve estimation accuracy. Spectrally, the perturbation introduces mixing between different eigenmodes of the expectation integral operator, which becomes especially useful when the integral equation is ill-defined. One source for such ill-definedness can be the curse of dimensionality. Our method performs across various dimensionality regimes, particularly when the dimensionality parameter $β$ which is defined through the number of samples $n$ and dimension $d$ as $n^β= d$, becomes large. Experimental results show that our first-order perturbative corrections can reduce prediction error by up to 99\% in high-dimensional ill-defined cases ($β> 0.7$) compared to standard ridge regression approaches. The performance improvement is maintained across a wide range of dimensions, with the advantage becoming more pronounced as dimensionality increases.
Fokker-Planck to Callan-Symanzik: evolution of weight matrices under training
Jan 16, 2025The dynamical evolution of a neural network during training has been an incredibly fascinating subject of study. First principal derivation of generic evolution of variables in statistical physics systems has proved useful when used to describe training dynamics conceptually, which in practice means numerically solving equations such as Fokker-Planck equation. Simulating entire networks inevitably runs into the curse of dimensionality. In this paper, we utilize Fokker-Planck to simulate the probability density evolution of individual weight matrices in the bottleneck layers of a simple 2-bottleneck-layered auto-encoder and compare the theoretical evolutions against the empirical ones by examining the output data distributions. We also derive physically relevant partial differential equations such as Callan-Symanzik and Kardar-Parisi-Zhang equations from the dynamical equation we have.
Deeply-Supervised Recurrent Convolutional Neural Network for Saliency Detection
Aug 18, 2016
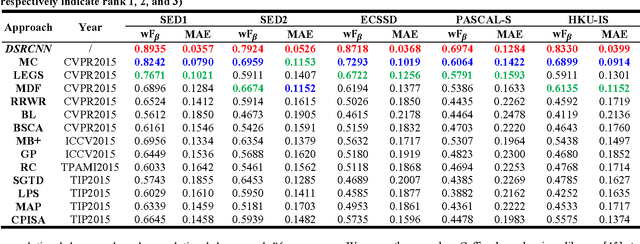
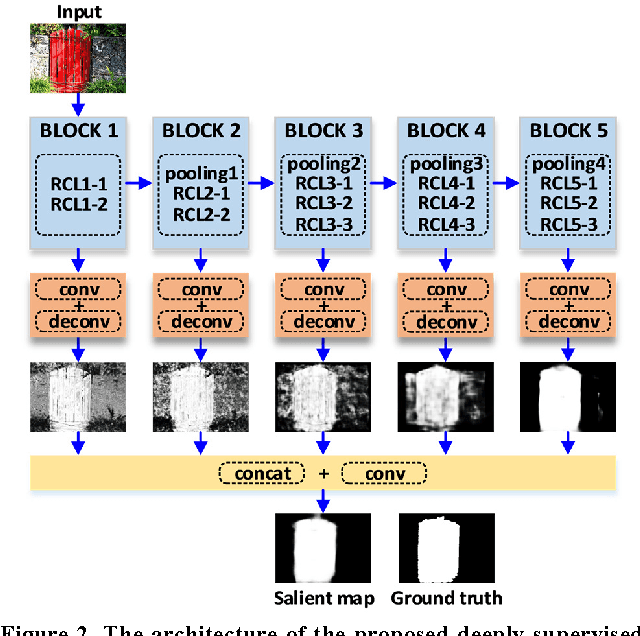
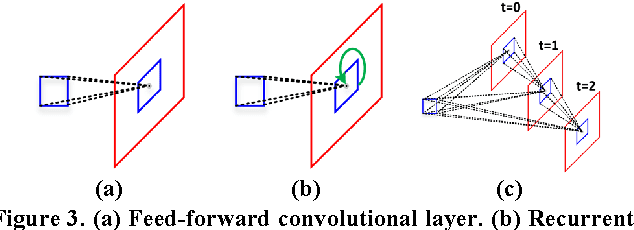
This paper proposes a novel saliency detection method by developing a deeply-supervised recurrent convolutional neural network (DSRCNN), which performs a full image-to-image saliency prediction. For saliency detection, the local, global, and contextual information of salient objects is important to obtain a high quality salient map. To achieve this goal, the DSRCNN is designed based on VGGNet-16. Firstly, the recurrent connections are incorporated into each convolutional layer, which can make the model more powerful for learning the contextual information. Secondly, side-output layers are added to conduct the deeply-supervised operation, which can make the model learn more discriminative and robust features by effecting the intermediate layers. Finally, all of the side-outputs are fused to integrate the local and global information to get the final saliency detection results. Therefore, the DSRCNN combines the advantages of recurrent convolutional neural networks and deeply-supervised nets. The DSRCNN model is tested on five benchmark datasets, and experimental results demonstrate that the proposed method significantly outperforms the state-of-the-art saliency detection approaches on all test datasets.