 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavehax: Aliasing-Free Neural Waveform Synthesis Based on 2D Convolution and Harmonic Prior for Reliable Complex Spectrogram Estimation
Nov 11, 2024



Neural vocoders often struggle with aliasing in latent feature spaces, caused by time-domain nonlinear operations and resampling layers. Aliasing folds high-frequency components into the low-frequency range, making aliased and original frequency components indistinguishable and introducing two practical issues. First, aliasing complicates the waveform generation process, as the subsequent layers must address these aliasing effects, increasing the computational complexity. Second, it limits extrapolation performance, particularly in handling high fundamental frequencies, which degrades the perceptual quality of generated speech waveforms. This paper demonstrates that 1) time-domain nonlinear operations inevitably introduce aliasing but provide a strong inductive bias for harmonic generation, and 2) time-frequency-domain processing can achieve aliasing-free waveform synthesis but lacks the inductive bias for effective harmonic generation. Building on this insight, we propose Wavehax, an aliasing-free neural WAVEform generator that integrates 2D convolution and a HArmonic prior for reliable Complex Spectrogram estimation. Experimental results show that Wavehax achieves speech quality comparable to existing high-fidelity neural vocoders and exhibits exceptional robustness in scenarios requiring high fundamental frequency extrapolation, where aliasing effects become typically severe. Moreover, Wavehax requires less than 5% of the multiply-accumulate operations and model parameters compared to HiFi-GAN V1, while achieving over four times faster CPU inference speed.
A Comparative Study of Voice Conversion Models with Large-Scale Speech and Singing Data: The T13 Systems for the Singing Voice Conversion Challenge 2023
Oct 08, 2023
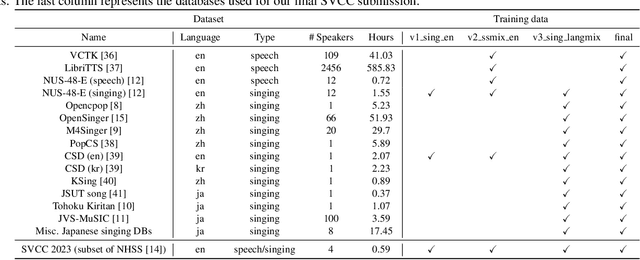

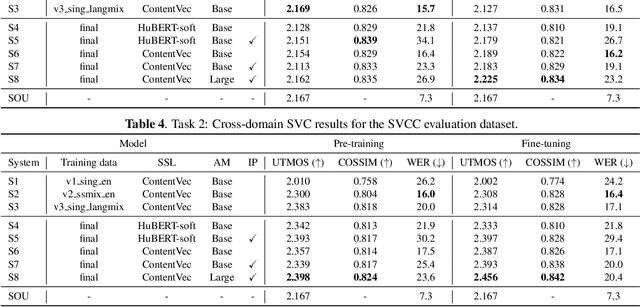
This paper presents our systems (denoted as T13) for the singing voice conversion challenge (SVCC) 2023. For both in-domain and cross-domain English singing voice conversion (SVC) tasks (Task 1 and Task 2), we adopt a recognition-synthesis approach with self-supervised learning-based representation. To achieve data-efficient SVC with a limited amount of target singer/speaker's data (150 to 160 utterances for SVCC 2023), we first train a diffusion-based any-to-any voice conversion model using publicly available large-scale 750 hours of speech and singing data. Then, we finetune the model for each target singer/speaker of Task 1 and Task 2. Large-scale listening tests conducted by SVCC 2023 show that our T13 system achieves competitive naturalness and speaker similarity for the harder cross-domain SVC (Task 2), which implies the generalization ability of our proposed method. Our objective evaluation results show that using large datasets is particularly beneficial for cross-domain SVC.
Source-Filter HiFi-GAN: Fast and Pitch Controllable High-Fidelity Neural Vocoder
Oct 31, 2022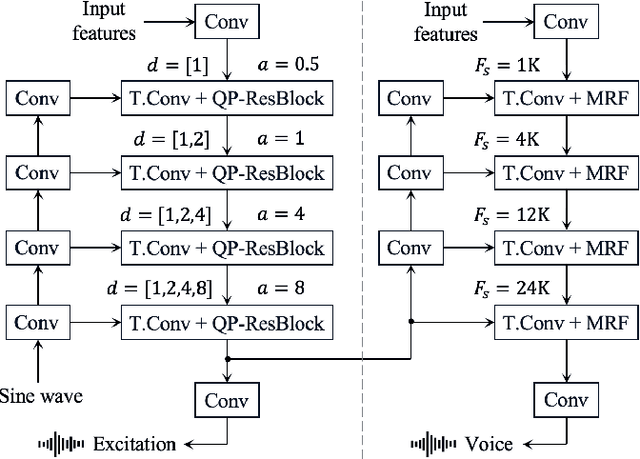
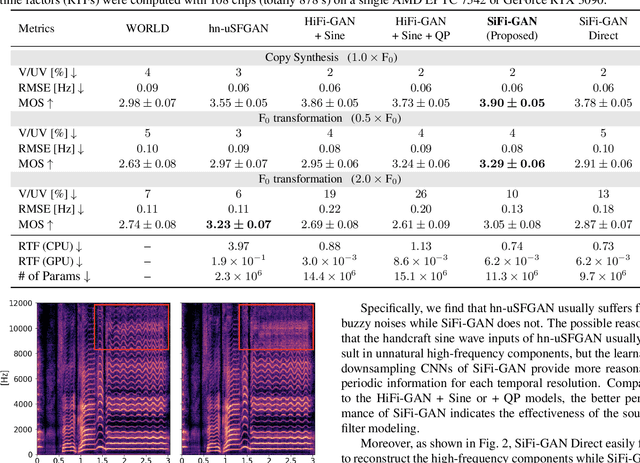
Our previous work, the unified source-filter GAN (uSFGAN) vocoder, introduced a novel architecture based on the source-filter theory into the parallel waveform generative adversarial network to achieve high voice quality and pitch controllability. However, the high temporal resolution inputs result in high computation costs. Although the HiFi-GAN vocoder achieves fast high-fidelity voice generation thanks to the efficient upsampling-based generator architecture, the pitch controllability is severely limited. To realize a fast and pitch-controllable high-fidelity neural vocoder, we introduce the source-filter theory into HiFi-GAN by hierarchically conditioning the resonance filtering network on a well-estimated source excitation information. According to the experimental results, our proposed method outperforms HiFi-GAN and uSFGAN on a singing voice generation in voice quality and synthesis speed on a single CPU. Furthermore, unlike the uSFGAN vocoder, the proposed method can be easily adopted/integrated in real-time applications and end-to-end systems.
NNSVS: A Neural Network-Based Singing Voice Synthesis Toolkit
Oct 28, 2022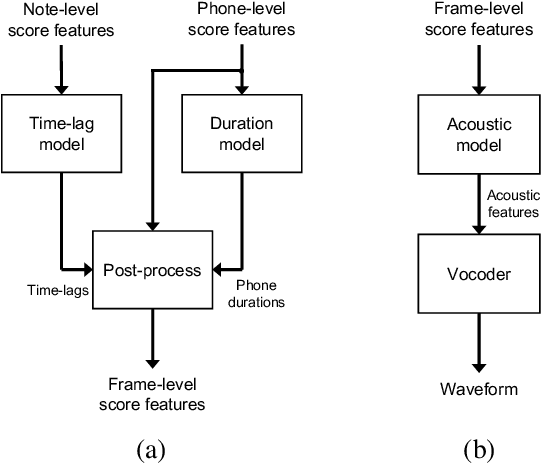
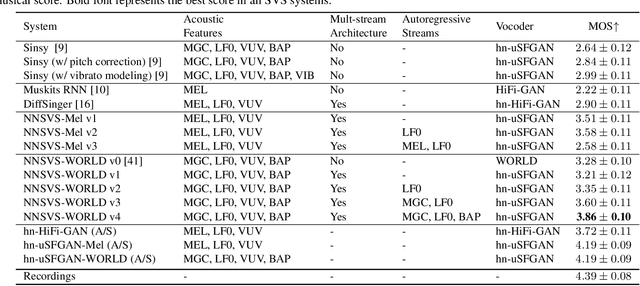
This paper describes the design of NNSVS, an open-source software for neural network-based singing voice synthesis research. NNSVS is inspired by Sinsy, an open-source pioneer in singing voice synthesis research, and provides many additional features such as multi-stream models, autoregressive fundamental frequency models, and neural vocoders. Furthermore, NNSVS provides extensive documentation and numerous scripts to build complete singing voice synthesis systems. Experimental results demonstrate that our best system significantly outperforms our reproduction of Sinsy and other baseline systems. The toolkit is available at https://github.com/nnsvs/nnsvs.
Nonparallel High-Quality Audio Super Resolution with Domain Adaptation and Resampling CycleGANs
Oct 28, 2022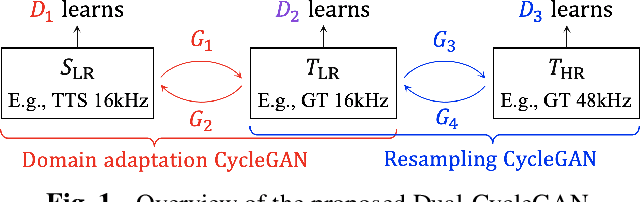
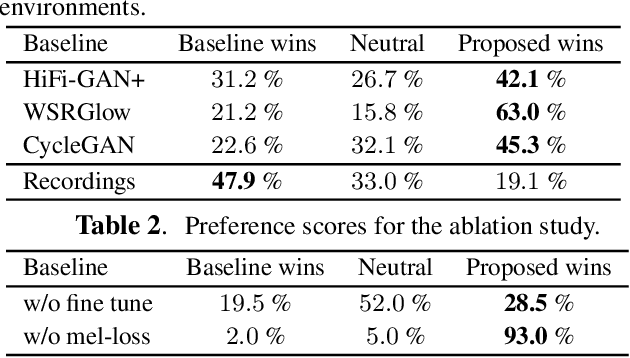

Neural audio super-resolution models are typically trained on low- and high-resolution audio signal pairs. Although these methods achieve highly accurate super-resolution if the acoustic characteristics of the input data are similar to those of the training data, challenges remain: the models suffer from quality degradation for out-of-domain data, and paired data are required for training. To address these problems, we propose Dual-CycleGAN, a high-quality audio super-resolution method that can utilize unpaired data based on two connected cycle consistent generative adversarial networks (CycleGAN). Our method decomposes the super-resolution method into domain adaptation and resampling processes to handle acoustic mismatch in the unpaired low- and high-resolution signals. The two processes are then jointly optimized within the CycleGAN framework. Experimental results verify that the proposed method significantly outperforms conventional methods when paired data are not available. Code and audio samples are available from https://chomeyama.github.io/DualCycleGAN-Demo/.
Unified Source-Filter GAN with Harmonic-plus-Noise Source Excitation Generation
May 12, 2022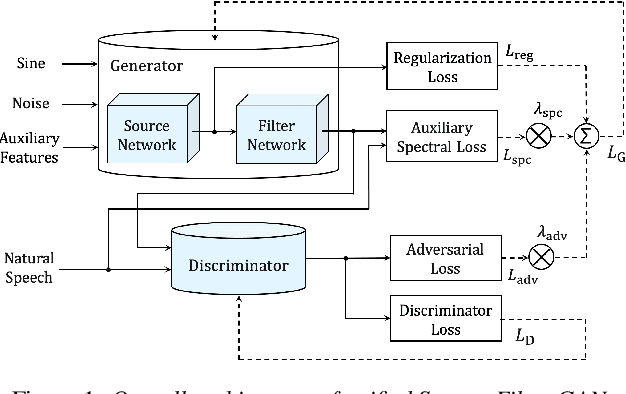
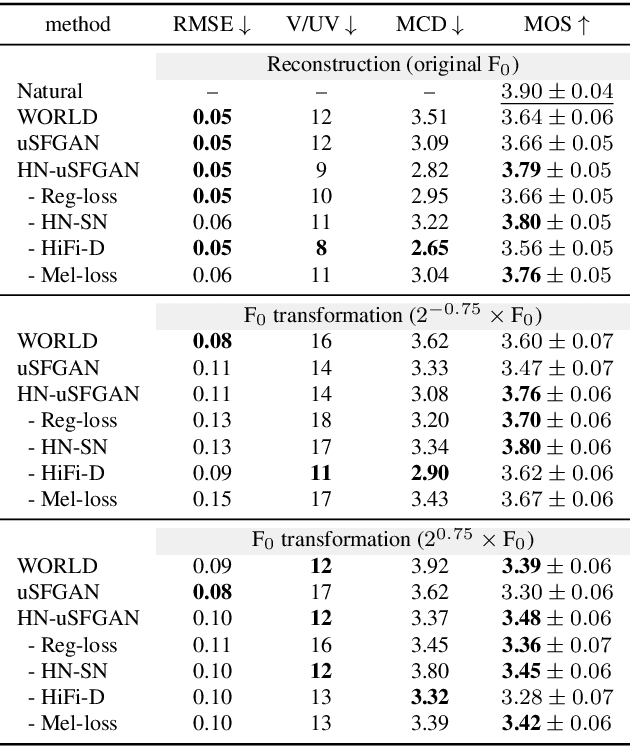
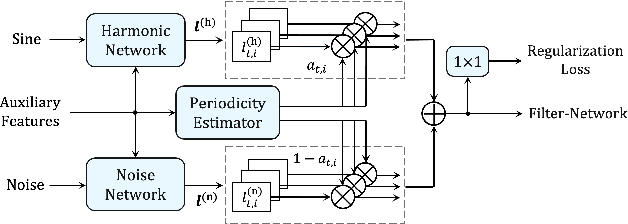
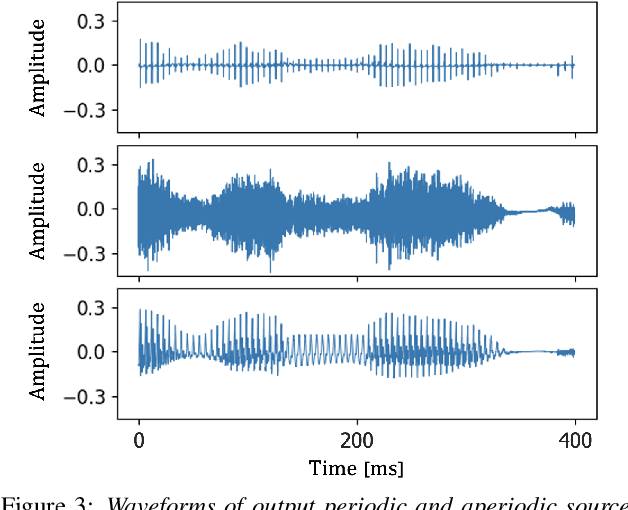
This paper introduces a unified source-filter network with a harmonic-plus-noise source excitation generation mechanism. In our previous work, we proposed unified Source-Filter GAN (uSFGAN) for developing a high-fidelity neural vocoder with flexible voice controllability using a unified source-filter neural network architecture. However, the capability of uSFGAN to model the aperiodic source excitation signal is insufficient, and there is still a gap in sound quality between the natural and generated speech. To improve the source excitation modeling and generated sound quality, a new source excitation generation network separately generating periodic and aperiodic components is proposed. The advanced adversarial training procedure of HiFiGAN is also adopted to replace that of Parallel WaveGAN used in the original uSFGAN. Both objective and subjective evaluation results show that the modified uSFGAN significantly improves the sound quality of the basic uSFGAN while maintaining the voice controllability.
Unified Source-Filter GAN: Unified Source-filter Network Based On Factorization of Quasi-Periodic Parallel WaveGAN
Apr 13, 2021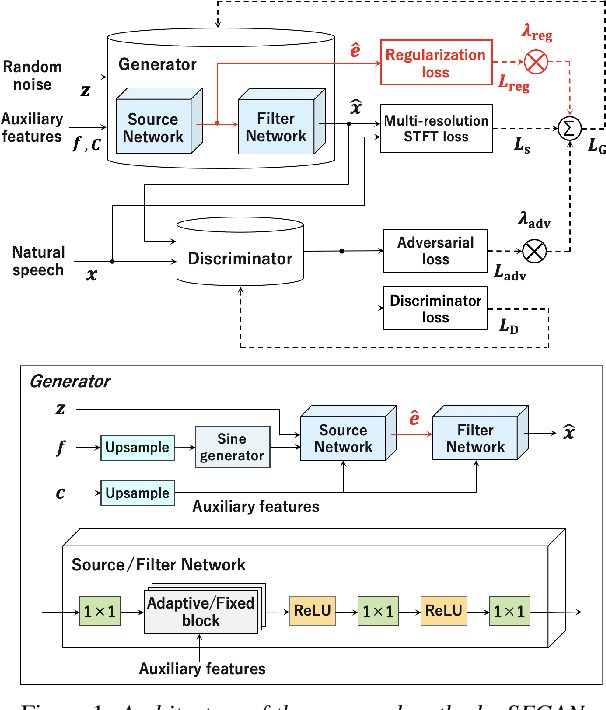
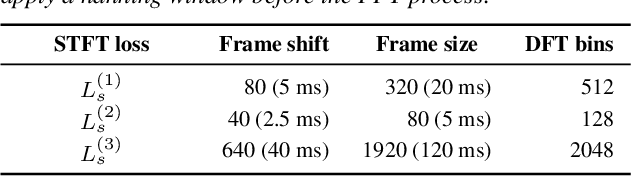
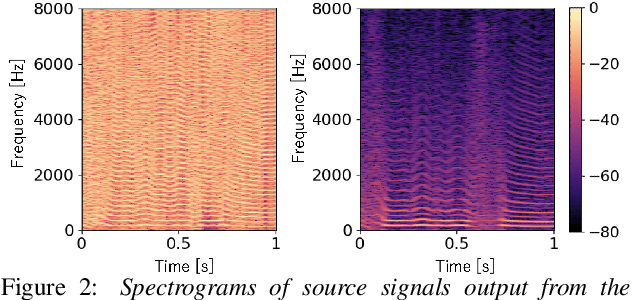
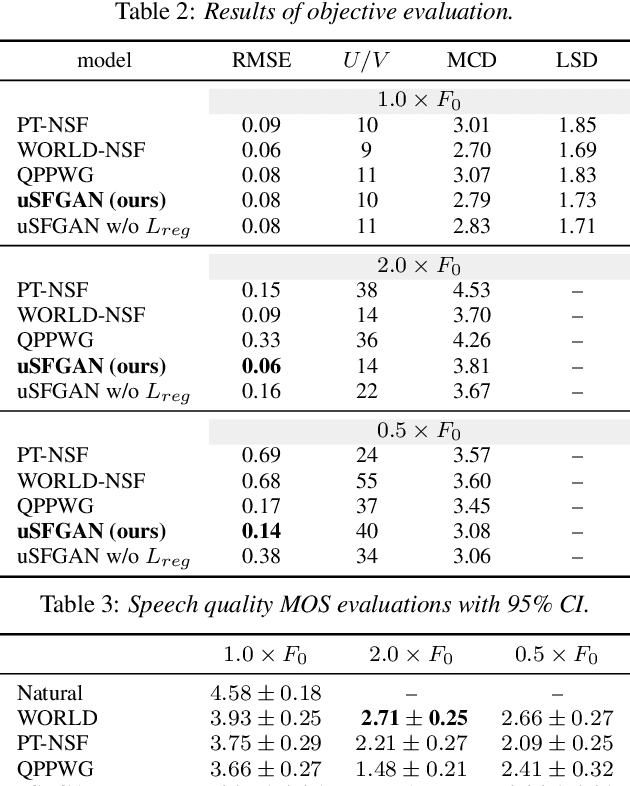
We propose a unified approach to data-driven source-filter modeling using a single neural network for developing a neural vocoder capable of generating high-quality synthetic speech waveforms while retaining flexibility of the source-filter model to control their voice characteristics. Our proposed network called unified source-filter generative adversarial networks (uSFGAN) is developed by factorizing quasi-periodic parallel WaveGAN (QPPWG), one of the neural vocoders based on a single neural network, into a source excitation generation network and a vocal tract resonance filtering network by additionally implementing a regularization loss. Moreover, inspired by neural source filter (NSF), only a sinusoidal waveform is additionally used as the simplest clue to generate a periodic source excitation waveform while minimizing the effect of approximations in the source filter model. The experimental results demonstrate that uSFGAN outperforms conventional neural vocoders, such as QPPWG and NSF in both speech quality and pitch controllability.