 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Voice Conversion Models with Large-Scale Speech and Singing Data: The T13 Systems for the Singing Voice Conversion Challenge 2023
Paper and Code

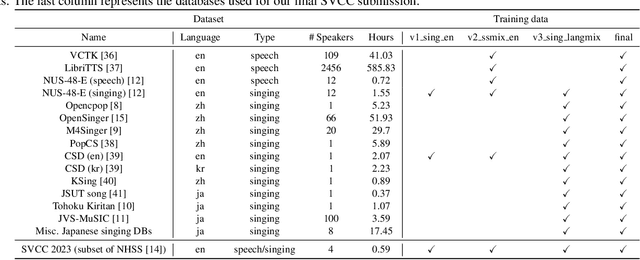

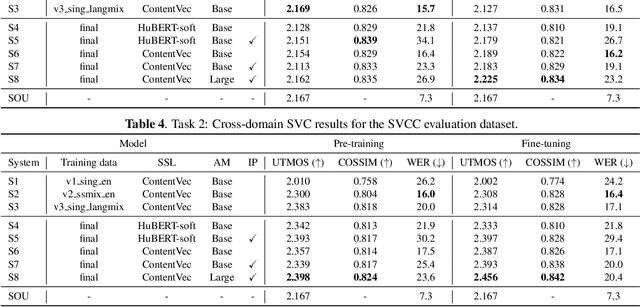
This paper presents our systems (denoted as T13) for the singing voice conversion challenge (SVCC) 2023. For both in-domain and cross-domain English singing voice conversion (SVC) tasks (Task 1 and Task 2), we adopt a recognition-synthesis approach with self-supervised learning-based representation. To achieve data-efficient SVC with a limited amount of target singer/speaker's data (150 to 160 utterances for SVCC 2023), we first train a diffusion-based any-to-any voice conversion model using publicly available large-scale 750 hours of speech and singing data. Then, we finetune the model for each target singer/speaker of Task 1 and Task 2. Large-scale listening tests conducted by SVCC 2023 show that our T13 system achieves competitive naturalness and speaker similarity for the harder cross-domain SVC (Task 2), which implies the generalization ability of our proposed method. Our objective evaluation results show that using large datasets is particularly beneficial for cross-domain SVC.