 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Source-Filter GAN with Harmonic-plus-Noise Source Excitation Generation
Paper and Code
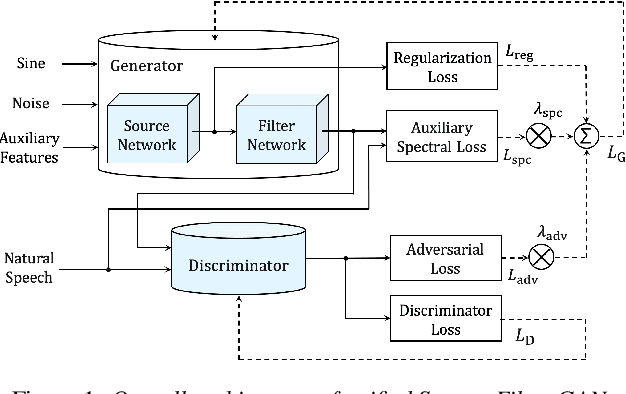
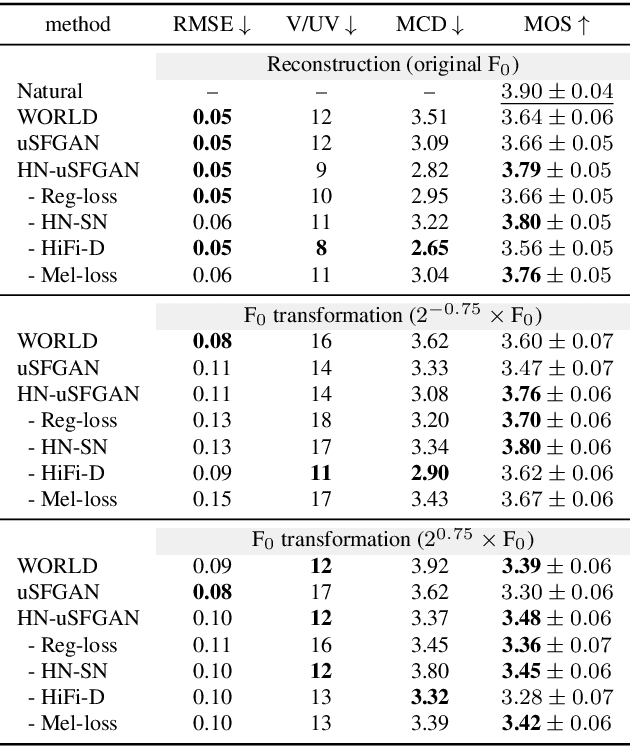
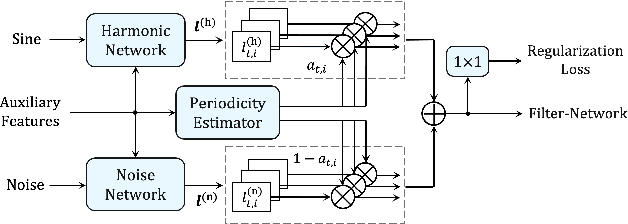
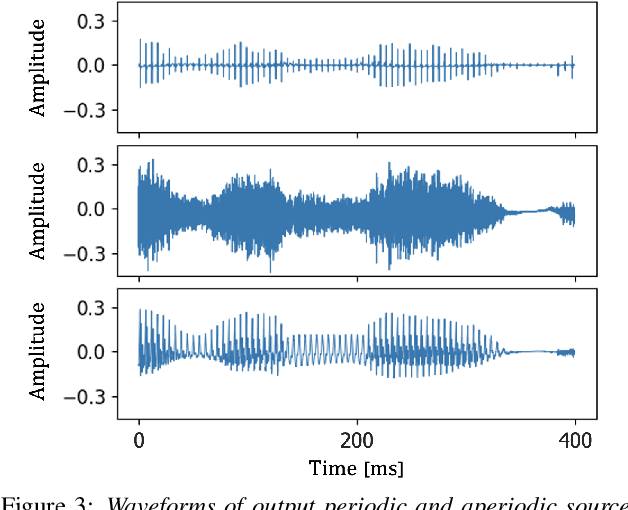
This paper introduces a unified source-filter network with a harmonic-plus-noise source excitation generation mechanism. In our previous work, we proposed unified Source-Filter GAN (uSFGAN) for developing a high-fidelity neural vocoder with flexible voice controllability using a unified source-filter neural network architecture. However, the capability of uSFGAN to model the aperiodic source excitation signal is insufficient, and there is still a gap in sound quality between the natural and generated speech. To improve the source excitation modeling and generated sound quality, a new source excitation generation network separately generating periodic and aperiodic components is proposed. The advanced adversarial training procedure of HiFiGAN is also adopted to replace that of Parallel WaveGAN used in the original uSFGAN. Both objective and subjective evaluation results show that the modified uSFGAN significantly improves the sound quality of the basic uSFGAN while maintaining the voice controllability.