 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource-Filter HiFi-GAN: Fast and Pitch Controllable High-Fidelity Neural Vocoder
Paper and Code
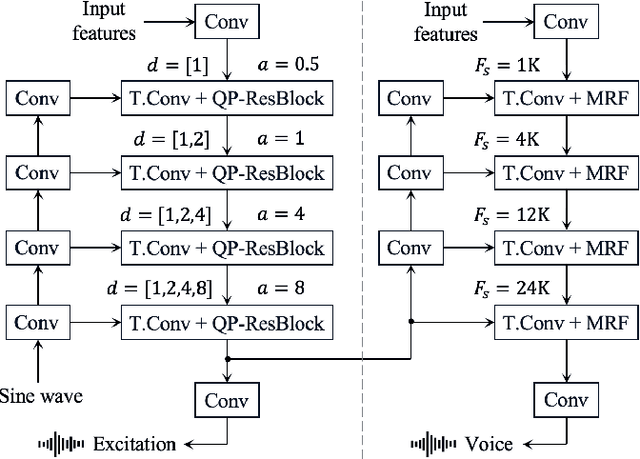
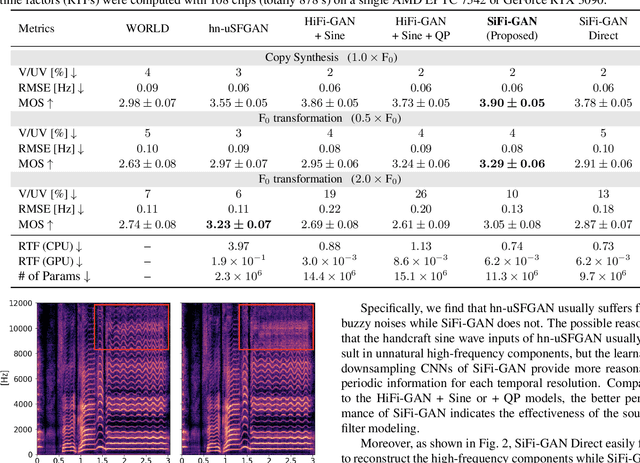
Our previous work, the unified source-filter GAN (uSFGAN) vocoder, introduced a novel architecture based on the source-filter theory into the parallel waveform generative adversarial network to achieve high voice quality and pitch controllability. However, the high temporal resolution inputs result in high computation costs. Although the HiFi-GAN vocoder achieves fast high-fidelity voice generation thanks to the efficient upsampling-based generator architecture, the pitch controllability is severely limited. To realize a fast and pitch-controllable high-fidelity neural vocoder, we introduce the source-filter theory into HiFi-GAN by hierarchically conditioning the resonance filtering network on a well-estimated source excitation information. According to the experimental results, our proposed method outperforms HiFi-GAN and uSFGAN on a singing voice generation in voice quality and synthesis speed on a single CPU. Furthermore, unlike the uSFGAN vocoder, the proposed method can be easily adopted/integrated in real-time applications and end-to-end systems.