 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation-Free MIDI-to-Audio Synthesis via Concatenative Synthesis and Generative Refinement
Paper and Code

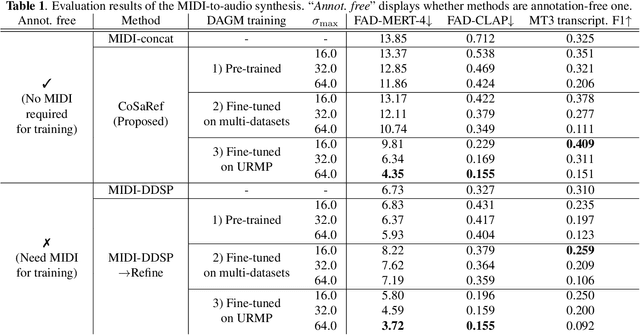
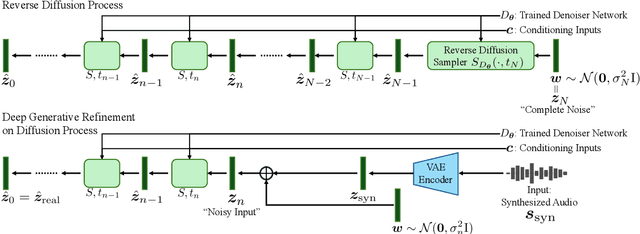
Recent MIDI-to-audio synthesis methods have employed deep neural networks to successfully generate high-quality and expressive instrumental tracks. However, these methods require MIDI annotations for supervised training, limiting the diversity of the output audio in terms of instrument timbres, and expression styles. We propose CoSaRef, a MIDI-to-audio synthesis method that can be developed without MIDI-audio paired datasets. CoSaRef first performs concatenative synthesis based on MIDI inputs and then refines the resulting audio into realistic tracks using a diffusion-based deep generative model trained on audio-only datasets. This approach enhances the diversity of audio timbres and expression styles. It also allows for control over the output timbre based on audio sample selection, similar to traditional functions in digital audio workstations. Experiments show that while inherently capable of generating general tracks with high control over timbre, CoSaRef can also perform comparably to conventional methods in generating realistic audio.