 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining on the Test Model: Contamination in Ranking Distillation
Nov 04, 2024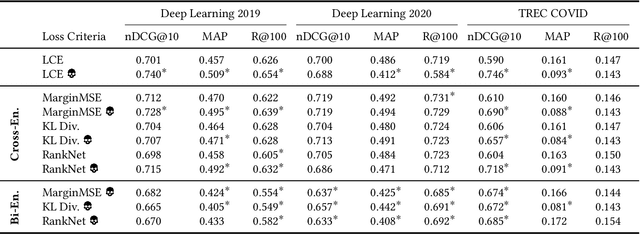
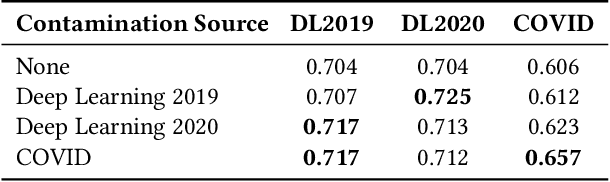
Neural approaches to ranking based on pre-trained language models are highly effective in ad-hoc search. However, the computational expense of these models can limit their application. As such, a process known as knowledge distillation is frequently applied to allow a smaller, efficient model to learn from an effective but expensive model. A key example of this is the distillation of expensive API-based commercial Large Language Models into smaller production-ready models. However, due to the opacity of training data and processes of most commercial models, one cannot ensure that a chosen test collection has not been observed previously, creating the potential for inadvertent data contamination. We, therefore, investigate the effect of a contaminated teacher model in a distillation setting. We evaluate several distillation techniques to assess the degree to which contamination occurs during distillation. By simulating a ``worst-case'' setting where the degree of contamination is known, we find that contamination occurs even when the test data represents a small fraction of the teacher's training samples. We, therefore, encourage caution when training using black-box teacher models where data provenance is ambiguous.