 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaB-ND: Long-Horizon Motion Planning with Branch-and-Bound and Neural Dynamics
Dec 12, 2024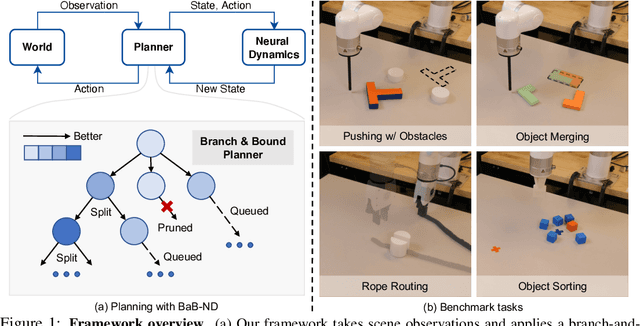
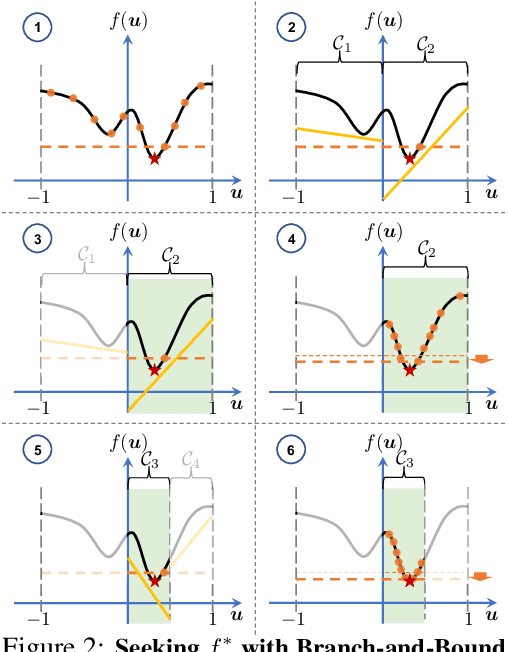
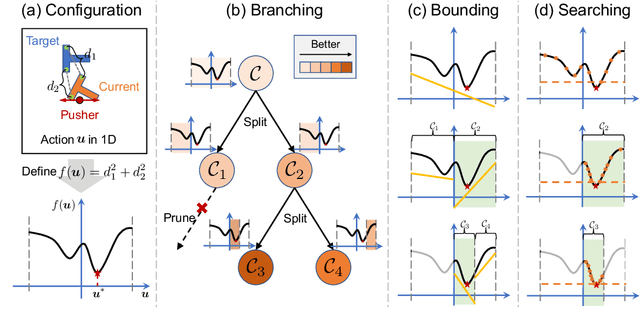

Neural-network-based dynamics models learned from observational data have shown strong predictive capabilities for scene dynamics in robotic manipulation tasks. However, their inherent non-linearity presents significant challenges for effective planning. Current planning methods, often dependent on extensive sampling or local gradient descent, struggle with long-horizon motion planning tasks involving complex contact events. In this paper, we present a GPU-accelerated branch-and-bound (BaB) framework for motion planning in manipulation tasks that require trajectory optimization over neural dynamics models. Our approach employs a specialized branching heuristics to divide the search space into subdomains, and applies a modified bound propagation method, inspired by the state-of-the-art neural network verifier alpha-beta-CROWN, to efficiently estimate objective bounds within these subdomains. The branching process guides planning effectively, while the bounding process strategically reduces the search space. Our framework achieves superior planning performance, generating high-quality state-action trajectories and surpassing existing methods in challenging, contact-rich manipulation tasks such as non-prehensile planar pushing with obstacles, object sorting, and rope routing in both simulated and real-world settings. Furthermore, our framework supports various neural network architectures, ranging from simple multilayer perceptrons to advanced graph neural dynamics models, and scales efficiently with different model sizes.
Deep Model Assembling
Dec 08, 2022



Large deep learning models have achieved remarkable success in many scenarios. However, training large models is usually challenging, e.g., due to the high computational cost, the unstable and painfully slow optimization procedure, and the vulnerability to overfitting. To alleviate these problems, this work studies a divide-and-conquer strategy, i.e., dividing a large model into smaller modules, training them independently, and reassembling the trained modules to obtain the target model. This approach is promising since it avoids directly training large models from scratch. Nevertheless, implementing this idea is non-trivial, as it is difficult to ensure the compatibility of the independently trained modules. In this paper, we present an elegant solution to address this issue, i.e., we introduce a global, shared meta model to implicitly link all the modules together. This enables us to train highly compatible modules that collaborate effectively when they are assembled together. We further propose a module incubation mechanism that enables the meta model to be designed as an extremely shallow network. As a result, the additional overhead introduced by the meta model is minimalized. Though conceptually simple, our method significantly outperforms end-to-end (E2E) training in terms of both final accuracy and training efficiency. For example, on top of ViT-Huge, it improves the accuracy by 2.7% compared to the E2E baseline on ImageNet-1K, while saving the training cost by 43% in the meantime. Code is available at https://github.com/LeapLabTHU/Model-Assembling.