 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRIS: Integrated Retinal Functionality in Image Sensors
Aug 14, 2022Neuromorphic image sensors draw inspiration from the biological retina to implement visual computations in electronic hardware. Gain control in phototransduction and temporal differentiation at the first retinal synapse inspired the first generation of neuromorphic sensors, but processing in downstream retinal circuits, much of which has been discovered in the past decade, has not been implemented in image sensor technology. We present a technology-circuit co-design solution that implements two motion computations occurring at the output of the retina that could have wide applications for vision based decision making in dynamic environments. Our simulations on Globalfoundries 22nm technology node show that, by taking advantage of the recent advances in semiconductor chip stacking technology, the proposed retina-inspired circuits can be fabricated on image sensing platforms in existing semiconductor foundries. Integrated Retinal Functionality in Image Sensors (IRIS) technology could drive advances in machine vision applications that demand robust, high-speed, energy-efficient and low-bandwidth real-time decision making.
Long-Term, in-the-Wild Study of Feedback about Speech Intelligibility for K-12 Students Attending Class via a Telepresence Robot
Aug 24, 2021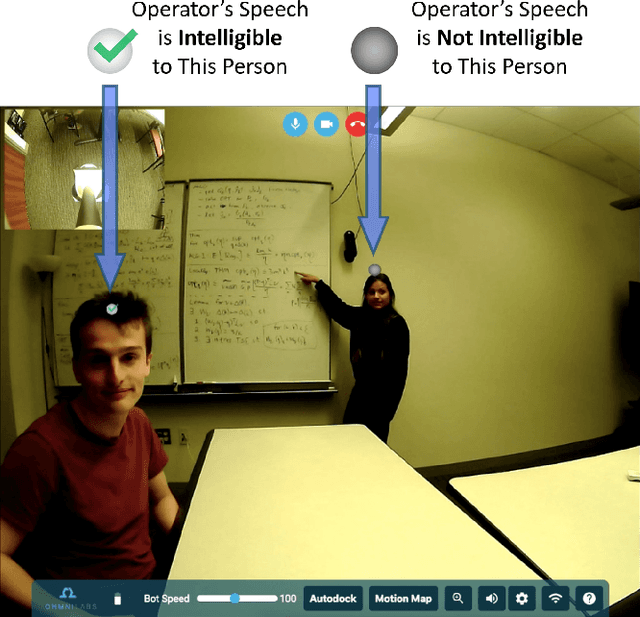

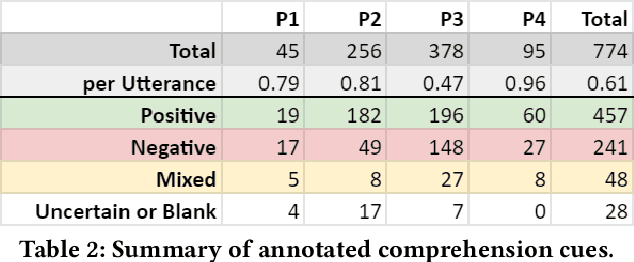
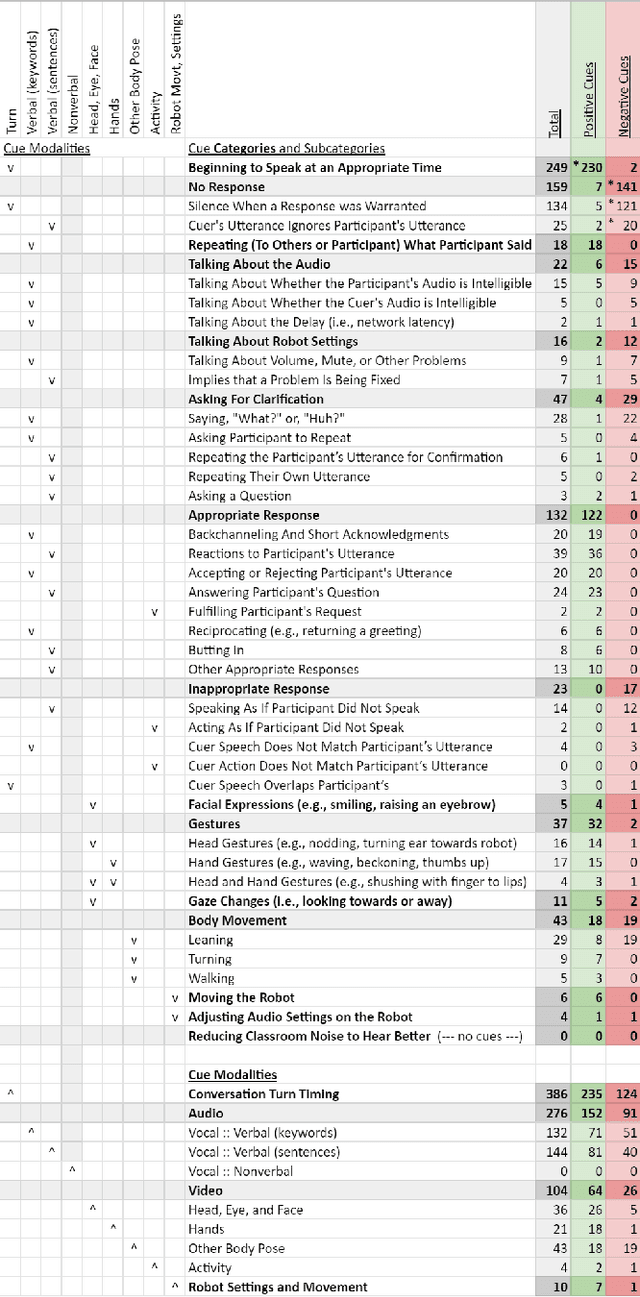
Telepresence robots offer presence, embodiment, and mobility to remote users, making them promising options for homebound K-12 students. It is difficult, however, for robot operators to know how well they are being heard in remote and noisy classroom environments. One solution is to estimate the operator's speech intelligibility to their listeners in order to provide feedback about it to the operator. This work contributes the first evaluation of a speech intelligibility feedback system for homebound K-12 students attending class remotely. In our four long-term, in-the-wild deployments we found that students speak at different volumes instead of adjusting the robot's volume, and that detailed audio calibration and network latency feedback are needed. We also contribute the first findings about the types and frequencies of multimodal comprehension cues given to homebound students by listeners in the classroom. By annotating and categorizing over 700 cues, we found that the most common cue modalities were conversation turn timing and verbal content. Conversation turn timing cues occurred more frequently overall, whereas verbal content cues contained more information and might be the most frequent modality for negative cues. Our work provides recommendations for telepresence systems that could intervene to ensure that remote users are being heard.