 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSite-specific Deterministic Temperature and Humidity Forecasts with Explainable and Reliable Machine Learning
Apr 04, 2024Site-specific weather forecasts are essential to accurate prediction of power demand and are consequently of great interest to energy operators. However, weather forecasts from current numerical weather prediction (NWP) models lack the fine-scale detail to capture all important characteristics of localised real-world sites. Instead they provide weather information representing a rectangular gridbox (usually kilometres in size). Even after post-processing and bias correction, area-averaged information is usually not optimal for specific sites. Prior work on site optimised forecasts has focused on linear methods, weighted consensus averaging, time-series methods, and others. Recent developments in machine learning (ML) have prompted increasing interest in applying ML as a novel approach towards this problem. In this study, we investigate the feasibility of optimising forecasts at sites by adopting the popular machine learning model gradient boosting decision tree, supported by the Python version of the XGBoost package. Regression trees have been trained with historical NWP and site observations as training data, aimed at predicting temperature and dew point at multiple site locations across Australia. We developed a working ML framework, named 'Multi-SiteBoost' and initial testing results show a significant improvement compared with gridded values from bias-corrected NWP models. The improvement from XGBoost is found to be comparable with non-ML methods reported in literature. With the insights provided by SHapley Additive exPlanations (SHAP), this study also tests various approaches to understand the ML predictions and increase the reliability of the forecasts generated by ML.
FourCastNeXt: Improving FourCastNet Training with Limited Compute
Jan 10, 2024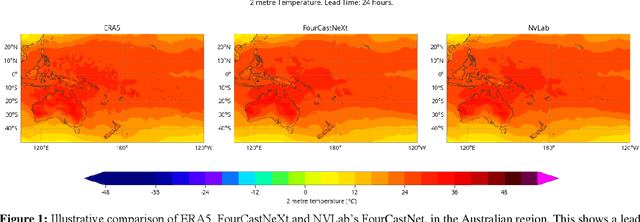

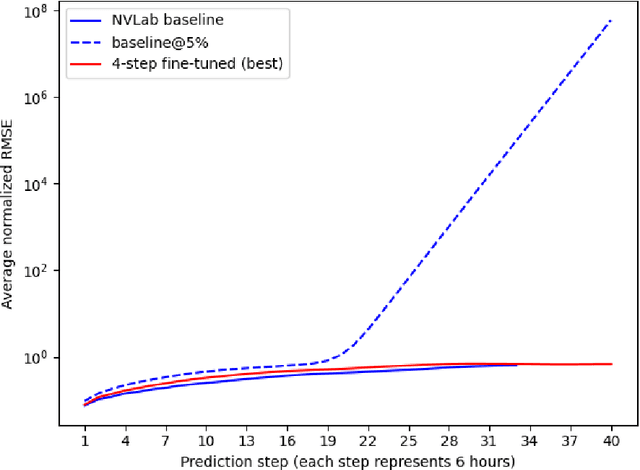
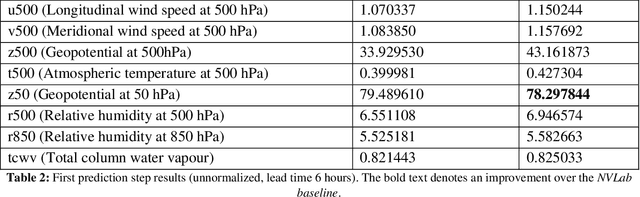
Recently, the FourCastNet Neural Earth System Model (NESM) has shown impressive results on predicting various atmospheric variables, trained on the ERA5 reanalysis dataset. While FourCastNet enjoys quasi-linear time and memory complexity in sequence length compared to quadratic complexity in vanilla transformers, training FourCastNet on ERA5 from scratch still requires large amount of compute resources, which is expensive or even inaccessible to most researchers. In this work, we will show improved methods that can train FourCastNet using only 1% of the compute required by the baseline, while maintaining model performance or par or even better than the baseline.