 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate information state for approximate planning and reinforcement learning in partially observed systems
Paper and Code

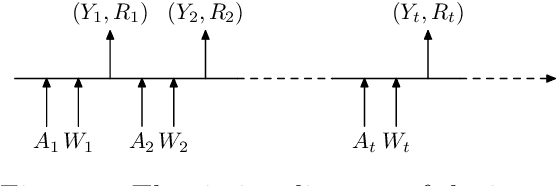
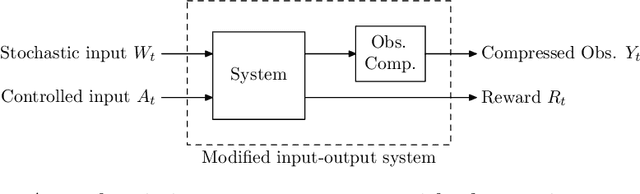
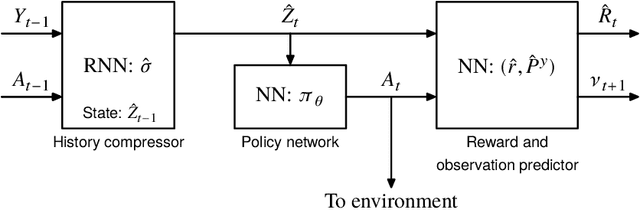
We propose a theoretical framework for approximate planning and learning in partially observed systems. Our framework is based on the fundamental notion of information state. We provide two equivalent definitions of information state---i) a function of history which is sufficient to compute the expected reward and predict its next value; ii) equivalently, a function of the history which can be recursively updated and is sufficient to compute the expected reward and predict the next observation. An information state always leads to a dynamic programming decomposition. Our key result is to show that if a function of the history (called approximate information state (AIS)) approximately satisfies the properties of the information state, then there is a corresponding approximate dynamic program. We show that the policy computed using this is approximately optimal with bounded loss of optimality. We show that several approximations in state, observation and action spaces in literature can be viewed as instances of AIS. In some of these cases, we obtain tighter bounds. A salient feature of AIS is that it can be learnt from data. We present AIS based multi-time scale policy gradient algorithms. and detailed numerical experiments with low, moderate and high dimensional environments.