 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Clinical Concept Extraction with Contextual Embedding
Paper and Code
Feb 22, 2019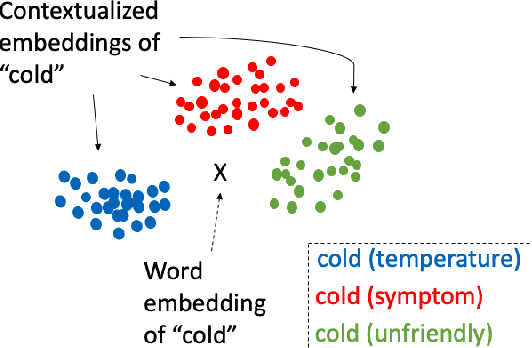
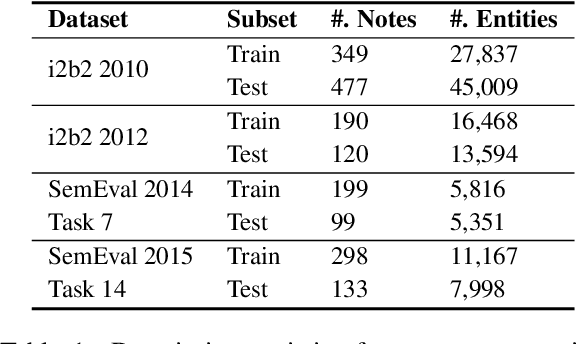
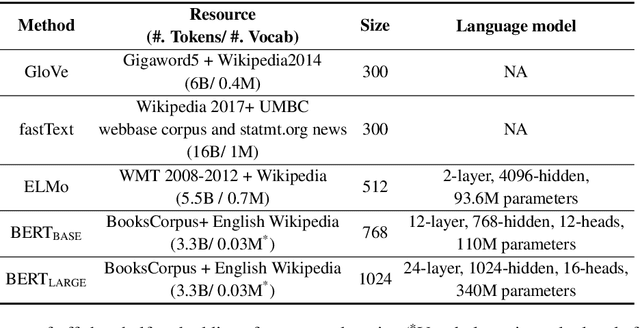
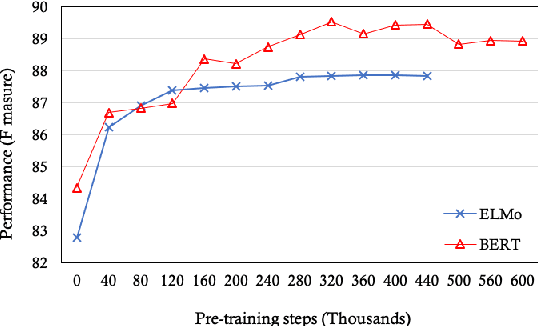
Neural network-based representations ("embeddings") have dramatically advanced natural language processing (NLP) tasks in the past few years. This certainly holds for clinical concept extraction, especially when combined with deep learning-based models. Recently, however, more advanced embedding methods and representations (e.g., ELMo, BERT) have further pushed the state-of-the-art in NLP. While these certainly improve clinical concept extraction as well, there are no commonly agreed upon best practices for how to integrate these representations for extracting concepts. The purpose of this study, then, is to explore the space of possible options in utilizing these new models, including comparing these to more traditional word embedding methods (word2vec, GloVe, fastText). We evaluate a battery of embedding methods on four clinical concept extraction corpora, explore effects of pre-training on extraction performance, and present an intuitive way to understand the semantic information encoded by advanced contextualized representations. Notably, we achieved new state-of-the-art performances across all four corpora.