 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTQ4SAM: Post-Training Quantization for Segment Anything
Paper and Code
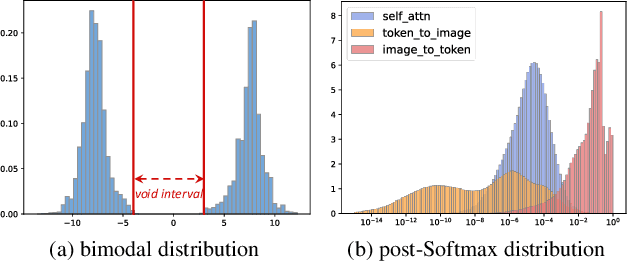
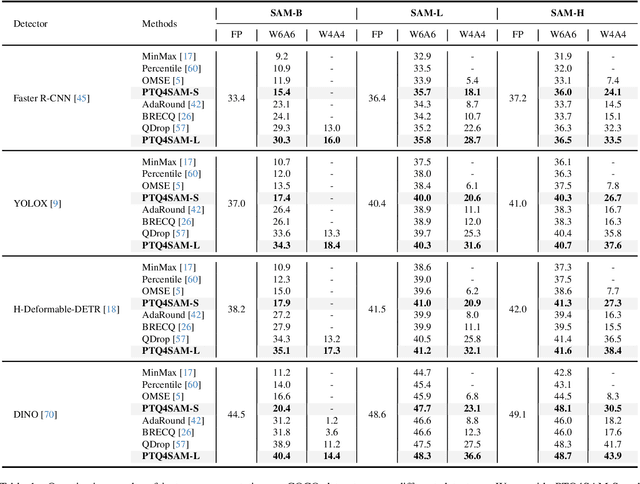
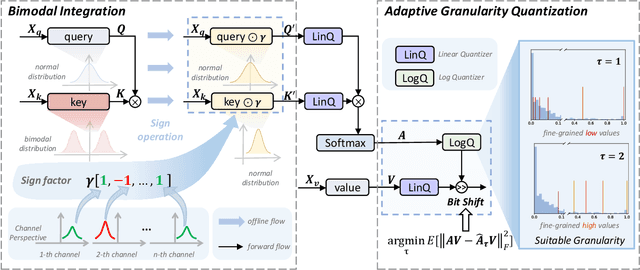
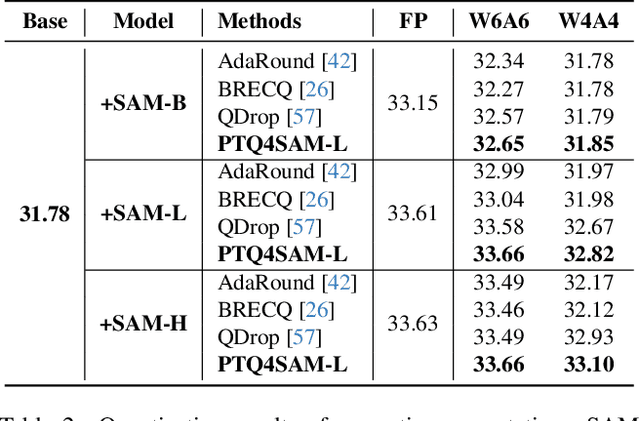
Segment Anything Model (SAM) has achieved impressive performance in many computer vision tasks. However, as a large-scale model, the immense memory and computation costs hinder its practical deployment. In this paper, we propose a post-training quantization (PTQ) framework for Segment Anything Model, namely PTQ4SAM. First, we investigate the inherent bottleneck of SAM quantization attributed to the bimodal distribution in post-Key-Linear activations. We analyze its characteristics from both per-tensor and per-channel perspectives, and propose a Bimodal Integration strategy, which utilizes a mathematically equivalent sign operation to transform the bimodal distribution into a relatively easy-quantized normal distribution offline. Second, SAM encompasses diverse attention mechanisms (i.e., self-attention and two-way cross-attention), resulting in substantial variations in the post-Softmax distributions. Therefore, we introduce an Adaptive Granularity Quantization for Softmax through searching the optimal power-of-two base, which is hardware-friendly. Extensive experimental results across various vision tasks (instance segmentation, semantic segmentation and object detection), datasets and model variants show the superiority of PTQ4SAM. For example, when quantizing SAM-L to 6-bit, we achieve lossless accuracy for instance segmentation, about 0.5\% drop with theoretical 3.9$\times$ acceleration. The code is available at \url{https://github.com/chengtao-lv/PTQ4SAM}.