 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSliM-LLM: Salience-Driven Mixed-Precision Quantization for Large Language Models
May 23, 2024



Large language models (LLMs) achieve remarkable performance in natural language understanding but require substantial computation and memory resources. Post-training quantization (PTQ) is a powerful compression technique extensively investigated in LLMs. However, existing PTQ methods are still not ideal in terms of accuracy and efficiency, especially with below 4 bit-widths. Standard PTQ methods using group-wise quantization suffer difficulties in quantizing LLMs accurately to such low-bit, but advanced methods remaining high-precision weights element-wisely are hard to realize their theoretical hardware efficiency. This paper presents a Salience-Driven Mixed-Precision Quantization scheme for LLMs, namely SliM-LLM. The scheme exploits the salience distribution of weights to determine optimal bit-width and quantizers for accurate LLM quantization, while aligning bit-width partition to groups for compact memory usage and fast integer inference. Specifically, the proposed SliM-LLM mainly relies on two novel techniques: (1) Salience-Determined Bit Allocation utilizes the clustering characteristics of salience distribution to allocate the bit-widths of each group, increasing the accuracy of quantized LLMs and maintaining the inference efficiency; (2) Salience-Weighted Quantizer Calibration optimizes the parameters of the quantizer by considering the element-wise salience within the group, balancing the maintenance of salient information and minimization of errors. Comprehensive experiments show that SliM-LLM significantly improves the accuracy of LLMs at ultra-low bits, e.g., 2-bit LLaMA-7B achieves a 5.5-times memory-saving than original model on NVIDIA A800 GPUs, and 48% decrease of perplexity compared to the state-of-the-art gradient-free PTQ method. Moreover, SliM-LLM+, which is integrated from the extension of SliM-LLM with gradient-based quantizers, further reduces perplexity by 35.1%.
BiLLM: Pushing the Limit of Post-Training Quantization for LLMs
Feb 06, 2024Pretrained large language models (LLMs) exhibit exceptional general language processing capabilities but come with significant demands on memory and computational resources. As a powerful compression technology, binarization can extremely reduce model weights to a mere 1 bit, lowering the expensive computation and memory requirements. However, existing quantization techniques fall short of maintaining LLM performance under ultra-low bit-widths. In response to this challenge, we present BiLLM, a groundbreaking 1-bit post-training quantization scheme tailored for pretrained LLMs. Based on the weight distribution of LLMs, BiLLM first identifies and structurally selects salient weights, and minimizes the compression loss through an effective binary residual approximation strategy. Moreover, considering the bell-shaped distribution of the non-salient weights, we propose an optimal splitting search to group and binarize them accurately. BiLLM achieving for the first time high-accuracy inference (e.g. 8.41 perplexity on LLaMA2-70B) with only 1.08-bit weights across various LLMs families and evaluation metrics, outperforms SOTA quantization methods of LLM by significant margins. Moreover, BiLLM enables the binarization process of the LLM with 7 billion weights within 0.5 hours on a single GPU, demonstrating satisfactory time efficiency.
OHQ: On-chip Hardware-aware Quantization
Sep 05, 2023



Quantization emerges as one of the most promising approaches for deploying advanced deep models on resource-constrained hardware. Mixed-precision quantization leverages multiple bit-width architectures to unleash the accuracy and efficiency potential of quantized models. However, existing mixed-precision quantization suffers exhaustive search space that causes immense computational overhead. The quantization process thus relies on separate high-performance devices rather than locally, which also leads to a significant gap between the considered hardware metrics and the real deployment.In this paper, we propose an On-chip Hardware-aware Quantization (OHQ) framework that performs hardware-aware mixed-precision quantization without accessing online devices. First, we construct the On-chip Quantization Awareness (OQA) pipeline, enabling perceive the actual efficiency metrics of the quantization operator on the hardware.Second, we propose Mask-guided Quantization Estimation (MQE) technique to efficiently estimate the accuracy metrics of operators under the constraints of on-chip-level computing power.By synthesizing network and hardware insights through linear programming, we obtain optimized bit-width configurations. Notably, the quantization process occurs on-chip entirely without any additional computing devices and data access. We demonstrate accelerated inference after quantization for various architectures and compression ratios, achieving 70% and 73% accuracy for ResNet-18 and MobileNetV3, respectively. OHQ improves latency by 15~30% compared to INT8 on deployment.
CyberLoc: Towards Accurate Long-term Visual Localization
Jan 06, 2023



This technical report introduces CyberLoc, an image-based visual localization pipeline for robust and accurate long-term pose estimation under challenging conditions. The proposed method comprises four modules connected in a sequence. First, a mapping module is applied to build accurate 3D maps of the scene, one map for each reference sequence if there exist multiple reference sequences under different conditions. Second, a single-image-based localization pipeline (retrieval--matching--PnP) is performed to estimate 6-DoF camera poses for each query image, one for each 3D map. Third, a consensus set maximization module is proposed to filter out outlier 6-DoF camera poses, and outputs one 6-DoF camera pose for a query. Finally, a robust pose refinement module is proposed to optimize 6-DoF query poses, taking candidate global 6-DoF camera poses and their corresponding global 2D-3D matches, sparse 2D-2D feature matches between consecutive query images and SLAM poses of the query sequence as input. Experiments on the 4seasons dataset show that our method achieves high accuracy and robustness. In particular, our approach wins the localization challenge of ECCV 2022 workshop on Map-based Localization for Autonomous Driving (MLAD-ECCV2022).
A Deep Reinforcement Learning Approach for Constrained Online Logistics Route Assignment
Sep 08, 2021
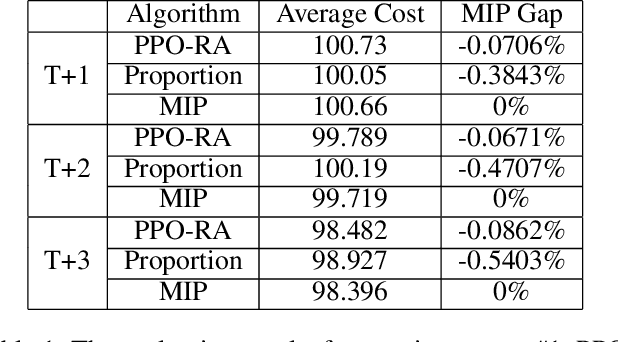

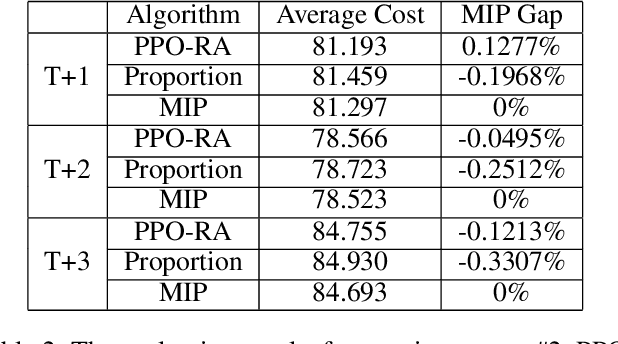
As online shopping prevails and e-commerce platforms emerge, there is a tremendous number of parcels being transported every day. Thus, it is crucial for the logistics industry on how to assign a candidate logistics route for each shipping parcel properly as it leaves a significant impact on the total logistics cost optimization and business constraints satisfaction such as transit hub capacity and delivery proportion of delivery providers. This online route-assignment problem can be viewed as a constrained online decision-making problem. Notably, the large amount (beyond ${10^5}$) of daily parcels, the variability and non-Markovian characteristics of parcel information impose difficulties on attaining (near-) optimal solution without violating constraints excessively. In this paper, we develop a model-free DRL approach named PPO-RA, in which Proximal Policy Optimization (PPO) is improved with dedicated techniques to address the challenges for route assignment (RA). The actor and critic networks use attention mechanism and parameter sharing to accommodate each incoming parcel with varying numbers and identities of candidate routes, without modeling non-Markovian parcel arriving dynamics since we make assumption of i.i.d. parcel arrival. We use recorded delivery parcel data to evaluate the performance of PPO-RA by comparing it with widely-used baselines via simulation. The results show the capability of the proposed approach to achieve considerable cost savings while satisfying most constraints.