 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyberLoc: Towards Accurate Long-term Visual Localization
Jan 06, 2023



This technical report introduces CyberLoc, an image-based visual localization pipeline for robust and accurate long-term pose estimation under challenging conditions. The proposed method comprises four modules connected in a sequence. First, a mapping module is applied to build accurate 3D maps of the scene, one map for each reference sequence if there exist multiple reference sequences under different conditions. Second, a single-image-based localization pipeline (retrieval--matching--PnP) is performed to estimate 6-DoF camera poses for each query image, one for each 3D map. Third, a consensus set maximization module is proposed to filter out outlier 6-DoF camera poses, and outputs one 6-DoF camera pose for a query. Finally, a robust pose refinement module is proposed to optimize 6-DoF query poses, taking candidate global 6-DoF camera poses and their corresponding global 2D-3D matches, sparse 2D-2D feature matches between consecutive query images and SLAM poses of the query sequence as input. Experiments on the 4seasons dataset show that our method achieves high accuracy and robustness. In particular, our approach wins the localization challenge of ECCV 2022 workshop on Map-based Localization for Autonomous Driving (MLAD-ECCV2022).
Aligning Linguistic Words and Visual Semantic Units for Image Captioning
Aug 06, 2019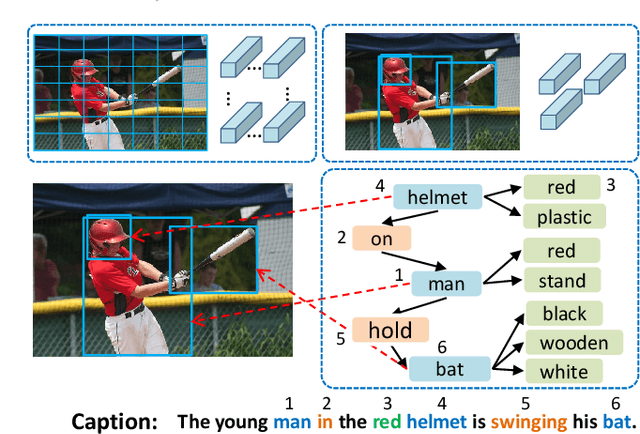
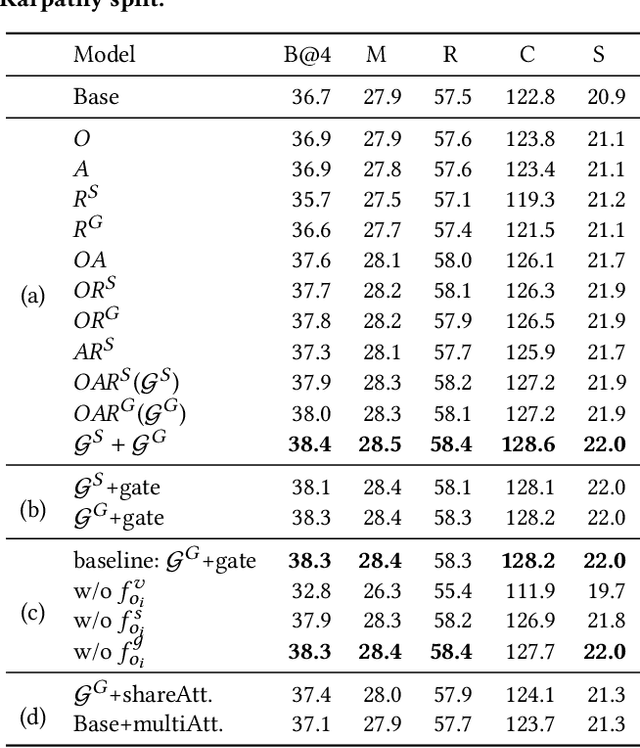
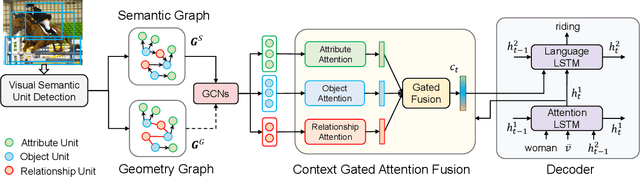
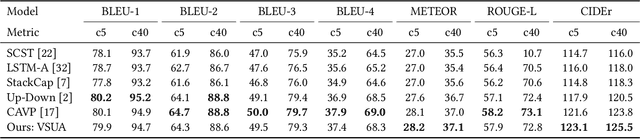
Image captioning attempts to generate a sentence composed of several linguistic words, which are used to describe objects, attributes, and interactions in an image, denoted as visual semantic units in this paper. Based on this view, we propose to explicitly model the object interactions in semantics and geometry based on Graph Convolutional Networks (GCNs), and fully exploit the alignment between linguistic words and visual semantic units for image captioning. Particularly, we construct a semantic graph and a geometry graph, where each node corresponds to a visual semantic unit, i.e., an object, an attribute, or a semantic (geometrical) interaction between two objects. Accordingly, the semantic (geometrical) context-aware embeddings for each unit are obtained through the corresponding GCN learning processers. At each time step, a context gated attention module takes as inputs the embeddings of the visual semantic units and hierarchically align the current word with these units by first deciding which type of visual semantic unit (object, attribute, or interaction) the current word is about, and then finding the most correlated visual semantic units under this type. Extensive experiments are conducted on the challenging MS-COCO image captioning dataset, and superior results are reported when comparing to state-of-the-art approaches.