 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Language Models Perform Robust Reasoning in Chain-of-thought Prompting with Noisy Rationales?
Oct 31, 2024

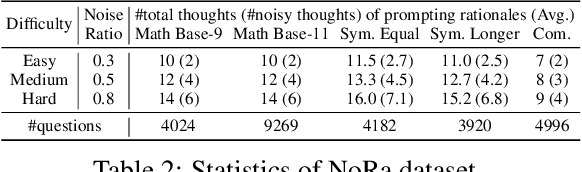
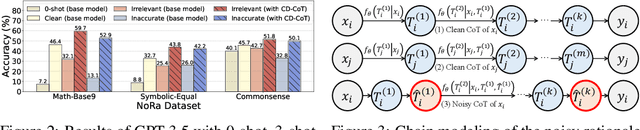
This paper investigates an under-explored challenge in large language models (LLMs): chain-of-thought prompting with noisy rationales, which include irrelevant or inaccurate reasoning thoughts within examples used for in-context learning. We construct NoRa dataset that is tailored to evaluate the robustness of reasoning in the presence of noisy rationales. Our findings on NoRa dataset reveal a prevalent vulnerability to such noise among current LLMs, with existing robust methods like self-correction and self-consistency showing limited efficacy. Notably, compared to prompting with clean rationales, base LLM drops by 1.4%-19.8% in accuracy with irrelevant thoughts and more drastically by 2.2%-40.4% with inaccurate thoughts. Addressing this challenge necessitates external supervision that should be accessible in practice. Here, we propose the method of contrastive denoising with noisy chain-of-thought (CD-CoT). It enhances LLMs' denoising-reasoning capabilities by contrasting noisy rationales with only one clean rationale, which can be the minimal requirement for denoising-purpose prompting. This method follows a principle of exploration and exploitation: (1) rephrasing and selecting rationales in the input space to achieve explicit denoising and (2) exploring diverse reasoning paths and voting on answers in the output space. Empirically, CD-CoT demonstrates an average improvement of 17.8% in accuracy over the base model and shows significantly stronger denoising capabilities than baseline methods. The source code is publicly available at: https://github.com/tmlr-group/NoisyRationales.
Rich Human Feedback for Text-to-Image Generation
Dec 15, 2023
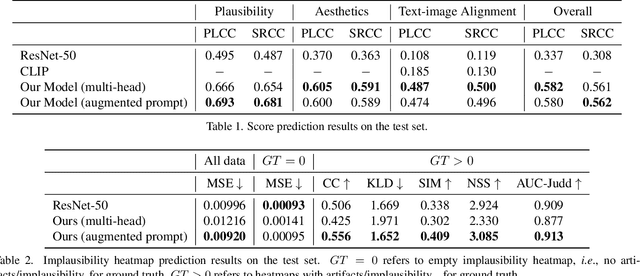
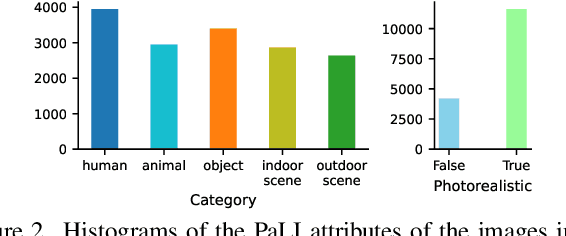
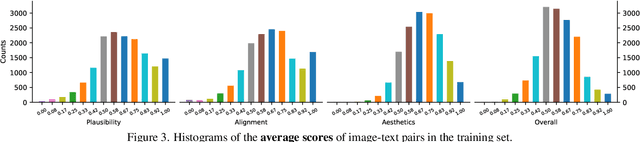
Recent Text-to-Image (T2I) generation models such as Stable Diffusion and Imagen have made significant progress in generating high-resolution images based on text descriptions. However, many generated images still suffer from issues such as artifacts/implausibility, misalignment with text descriptions, and low aesthetic quality. Inspired by the success of Reinforcement Learning with Human Feedback (RLHF) for large language models, prior works collected human-provided scores as feedback on generated images and trained a reward model to improve the T2I generation. In this paper, we enrich the feedback signal by (i) marking image regions that are implausible or misaligned with the text, and (ii) annotating which words in the text prompt are misrepresented or missing on the image. We collect such rich human feedback on 18K generated images and train a multimodal transformer to predict the rich feedback automatically. We show that the predicted rich human feedback can be leveraged to improve image generation, for example, by selecting high-quality training data to finetune and improve the generative models, or by creating masks with predicted heatmaps to inpaint the problematic regions. Notably, the improvements generalize to models (Muse) beyond those used to generate the images on which human feedback data were collected (Stable Diffusion variants).