 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models as Black-Box Optimizers for Vision-Language Models
Sep 25, 2023



Vision-language models (VLMs) pre-trained on web-scale datasets have demonstrated remarkable capabilities across a variety of vision and multimodal tasks. Currently, fine-tuning methods for VLMs mainly operate in a white-box setting, requiring access to model parameters for backpropagation. However, many VLMs rely on proprietary data and are not open-source, which restricts the use of white-box approaches for fine-tuning. Given that popular private large language models (LLMs) like ChatGPT still offer a language-based user interface, we aim to develop a novel fine-tuning approach for VLMs through natural language prompts, thereby avoiding the need to access model parameters, feature embeddings, or output logits. In this setup, we propose employing chat-based LLMs as black-box optimizers to search for the best text prompt on the illustrative task of few-shot image classification using CLIP. Specifically, we adopt an automatic "hill-climbing" procedure that converges on an effective prompt by evaluating the accuracy of current prompts and asking LLMs to refine them based on textual feedback, all within a conversational process without human-in-the-loop. In a challenging 1-shot learning setup, our simple approach surpasses the white-box continuous prompting method (CoOp) by an average of 1.5% across 11 datasets including ImageNet. Our approach also outperforms OpenAI's manually crafted prompts. Additionally, we highlight the advantage of conversational feedback that incorporates both positive and negative prompts, suggesting that LLMs can utilize the implicit "gradient" direction in textual feedback for a more efficient search. Lastly, we find that the text prompts generated through our strategy are not only more interpretable but also transfer well across different CLIP architectures in a black-box manner.
Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with Multimodal Models
Jan 18, 2023

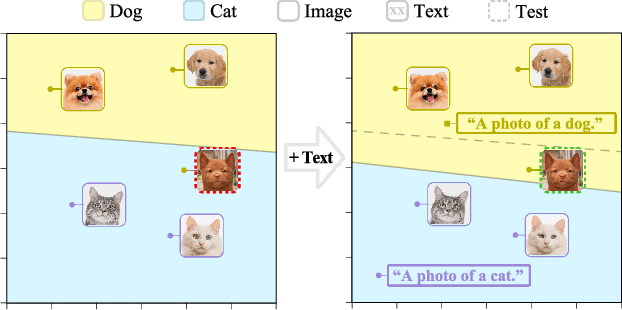

The ability to quickly learn a new task with minimal instruction - known as few-shot learning - is a central aspect of intelligent agents. Classical few-shot benchmarks make use of few-shot samples from a single modality, but such samples may not be sufficient to characterize an entire concept class. In contrast, humans use cross-modal information to learn new concepts efficiently. In this work, we demonstrate that one can indeed build a better ${\bf visual}$ dog classifier by ${\bf read}$ing about dogs and ${\bf listen}$ing to them bark. To do so, we exploit the fact that recent multimodal foundation models such as CLIP are inherently cross-modal, mapping different modalities to the same representation space. Specifically, we propose a simple cross-modal adaptation approach that learns from few-shot examples spanning different modalities. By repurposing class names as additional one-shot training samples, we achieve SOTA results with an embarrassingly simple linear classifier for vision-language adaptation. Furthermore, we show that our approach can benefit existing methods such as prefix tuning, adapters, and classifier ensembling. Finally, to explore other modalities beyond vision and language, we construct the first (to our knowledge) audiovisual few-shot benchmark and use cross-modal training to improve the performance of both image and audio classification.
PACS: A Dataset for Physical Audiovisual CommonSense Reasoning
Mar 21, 2022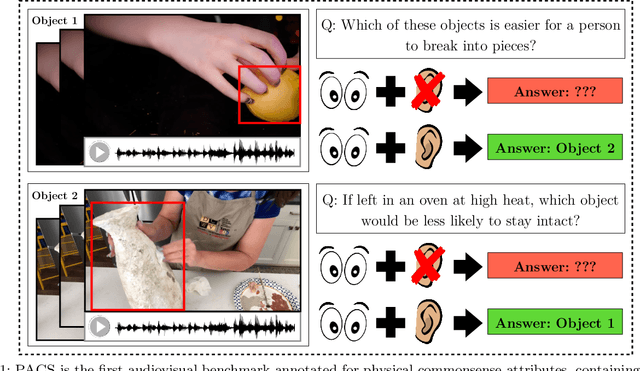
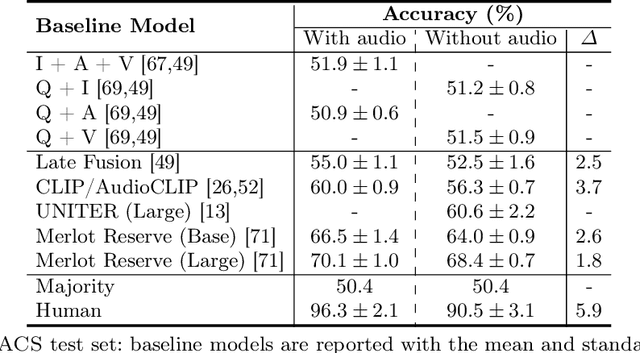
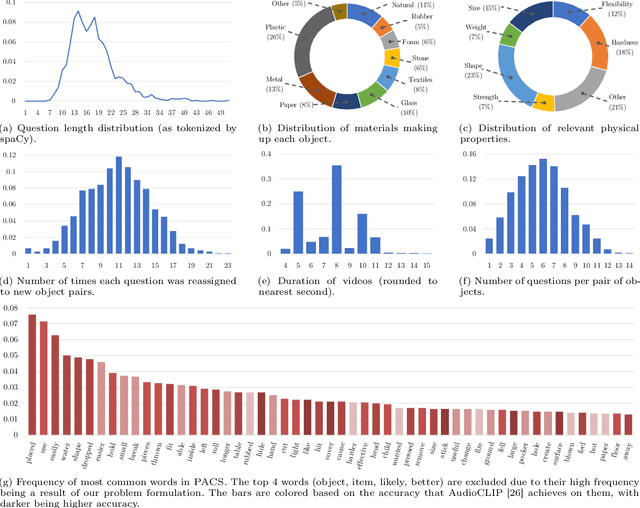
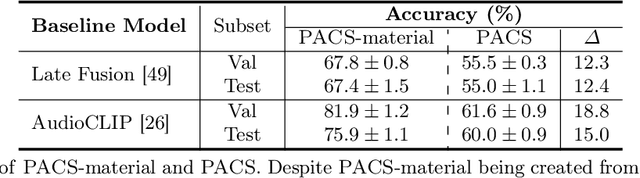
In order for AI to be safely deployed in real-world scenarios such as hospitals, schools, and the workplace, they should be able to reason about the physical world by understanding the physical properties and affordances of available objects, how they can be manipulated, and how they interact with other physical objects. This research field of physical commonsense reasoning is fundamentally a multi-sensory task since physical properties are manifested through multiple modalities, two of them being vision and acoustics. Our paper takes a step towards real-world physical commonsense reasoning by contributing PACS: the first audiovisual benchmark annotated for physical commonsense attributes. PACS contains a total of 13,400 question-answer pairs, involving 1,377 unique physical commonsense questions and 1,526 videos. Our dataset provides new opportunities to advance the research field of physical reasoning by bringing audio as a core component of this multimodal problem. Using PACS, we evaluate multiple state-of-the-art models on this new challenging task. While some models show promising results (70% accuracy), they all fall short of human performance (95% accuracy). We conclude the paper by demonstrating the importance of multimodal reasoning and providing possible avenues for future research.
Street Crossing Aid Using Light-weight CNNs for the Visually Impaired
Sep 14, 2019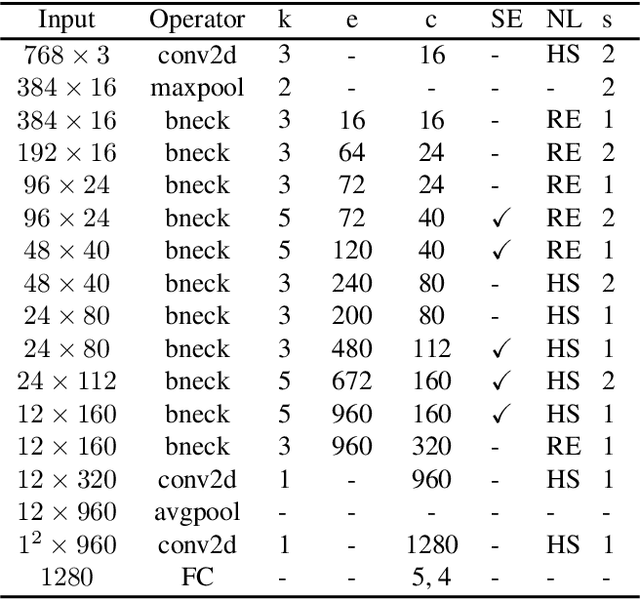

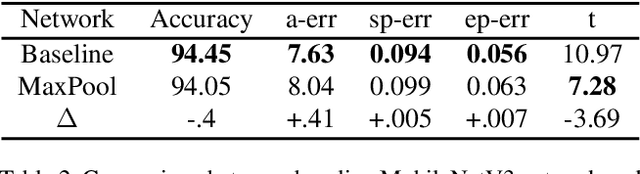

In this paper, we address an issue that the visually impaired commonly face while crossing intersections and propose a solution that takes form as a mobile application. The application utilizes a deep learning convolutional neural network model, LytNetV2, to output necessary information that the visually impaired may lack when without human companions or guide-dogs. A prototype of the application runs on iOS devices of versions 11 or above. It is designed for comprehensiveness, concision, accuracy, and computational efficiency through delivering the two most important pieces of information, pedestrian traffic light color and direction, required to cross the road in real-time. Furthermore, it is specifically aimed to support those facing financial burden as the solution takes the form of a free mobile application. Through the modification and utilization of key principles in MobileNetV3 such as depthwise seperable convolutions and squeeze-excite layers, the deep neural network model achieves a classification accuracy of 96% and average angle error of 6.15 degrees, while running at a frame rate of 16.34 frames per second. Additionally, the model is trained as an image classifier, allowing for a faster and more accurate model. The network is able to outperform other methods such as object detection and non-deep learning algorithms in both accuracy and thoroughness. The information is delivered through both auditory signals and vibrations, and it has been tested on seven visually impaired and has received above satisfactory responses.
LYTNet: A Convolutional Neural Network for Real-Time Pedestrian Traffic Lights and Zebra Crossing Recognition for the Visually Impaired
Jul 23, 2019


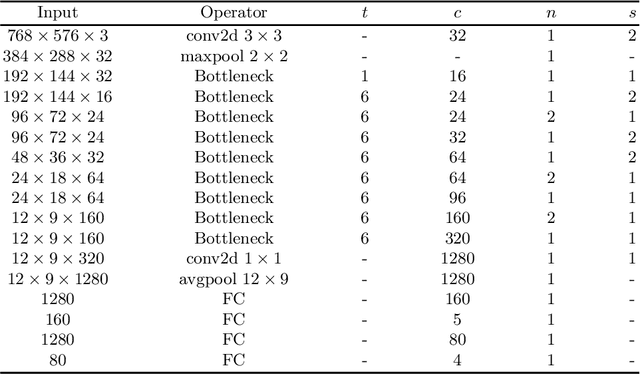
Currently, the visually impaired rely on either a sighted human, guide dog, or white cane to safely navigate. However, the training of guide dogs is extremely expensive, and canes cannot provide essential information regarding the color of traffic lights and direction of crosswalks. In this paper, we propose a deep learning based solution that provides information regarding the traffic light mode and the position of the zebra crossing. Previous solutions that utilize machine learning only provide one piece of information and are mostly binary: only detecting red or green lights. The proposed convolutional neural network, LYTNet, is designed for comprehensiveness, accuracy, and computational efficiency. LYTNet delivers both of the two most important pieces of information for the visually impaired to cross the road. We provide five classes of pedestrian traffic lights rather than the commonly seen three or four, and a direction vector representing the midline of the zebra crossing that is converted from the 2D image plane to real-world positions. We created our own dataset of pedestrian traffic lights containing over 5000 photos taken at hundreds of intersections in Shanghai. The experiments carried out achieve a classification accuracy of 94%, average angle error of 6.35 degrees, with a frame rate of 20 frames per second when testing the network on an iPhone 7 with additional post-processing steps.