 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreet Crossing Aid Using Light-weight CNNs for the Visually Impaired
Sep 14, 2019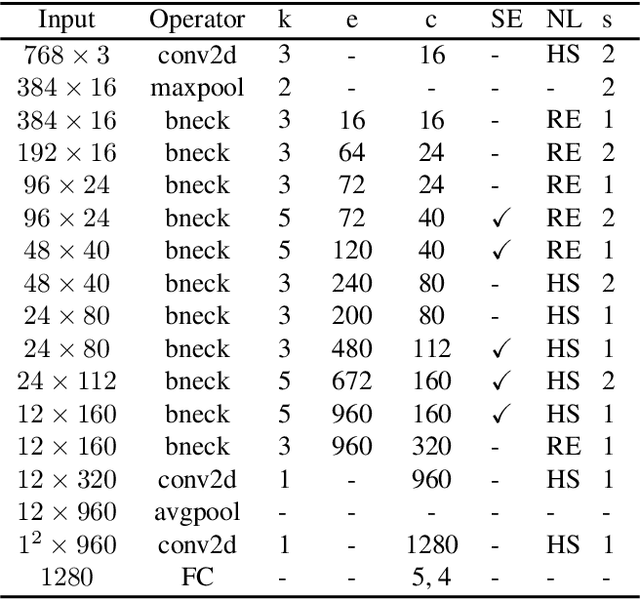

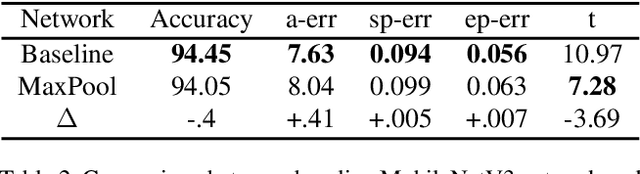

In this paper, we address an issue that the visually impaired commonly face while crossing intersections and propose a solution that takes form as a mobile application. The application utilizes a deep learning convolutional neural network model, LytNetV2, to output necessary information that the visually impaired may lack when without human companions or guide-dogs. A prototype of the application runs on iOS devices of versions 11 or above. It is designed for comprehensiveness, concision, accuracy, and computational efficiency through delivering the two most important pieces of information, pedestrian traffic light color and direction, required to cross the road in real-time. Furthermore, it is specifically aimed to support those facing financial burden as the solution takes the form of a free mobile application. Through the modification and utilization of key principles in MobileNetV3 such as depthwise seperable convolutions and squeeze-excite layers, the deep neural network model achieves a classification accuracy of 96% and average angle error of 6.15 degrees, while running at a frame rate of 16.34 frames per second. Additionally, the model is trained as an image classifier, allowing for a faster and more accurate model. The network is able to outperform other methods such as object detection and non-deep learning algorithms in both accuracy and thoroughness. The information is delivered through both auditory signals and vibrations, and it has been tested on seven visually impaired and has received above satisfactory responses.
LYTNet: A Convolutional Neural Network for Real-Time Pedestrian Traffic Lights and Zebra Crossing Recognition for the Visually Impaired
Jul 23, 2019


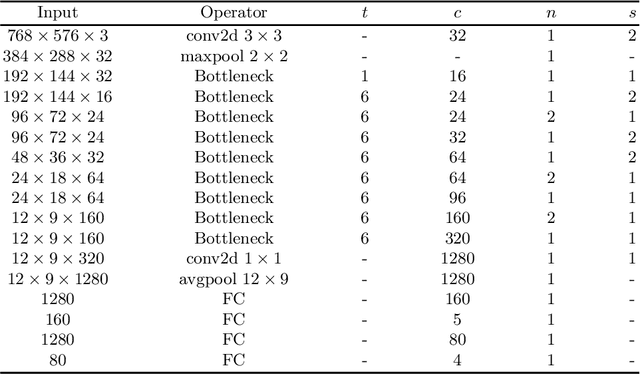
Currently, the visually impaired rely on either a sighted human, guide dog, or white cane to safely navigate. However, the training of guide dogs is extremely expensive, and canes cannot provide essential information regarding the color of traffic lights and direction of crosswalks. In this paper, we propose a deep learning based solution that provides information regarding the traffic light mode and the position of the zebra crossing. Previous solutions that utilize machine learning only provide one piece of information and are mostly binary: only detecting red or green lights. The proposed convolutional neural network, LYTNet, is designed for comprehensiveness, accuracy, and computational efficiency. LYTNet delivers both of the two most important pieces of information for the visually impaired to cross the road. We provide five classes of pedestrian traffic lights rather than the commonly seen three or four, and a direction vector representing the midline of the zebra crossing that is converted from the 2D image plane to real-world positions. We created our own dataset of pedestrian traffic lights containing over 5000 photos taken at hundreds of intersections in Shanghai. The experiments carried out achieve a classification accuracy of 94%, average angle error of 6.35 degrees, with a frame rate of 20 frames per second when testing the network on an iPhone 7 with additional post-processing steps.