 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust End-to-End Focal Liver Lesion Detection using Unregistered Multiphase Computed Tomography Images
Dec 17, 2021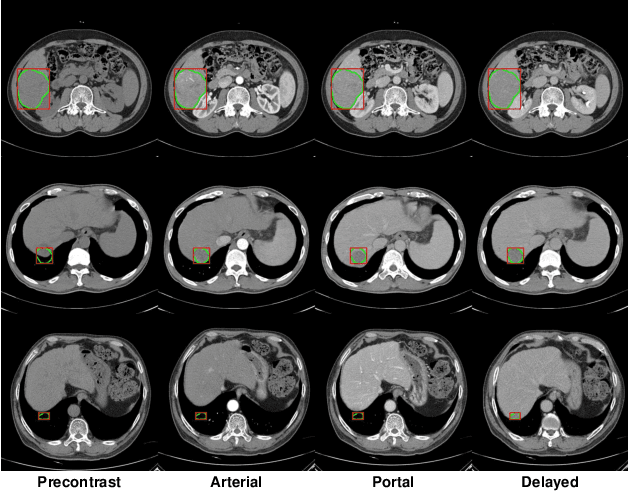
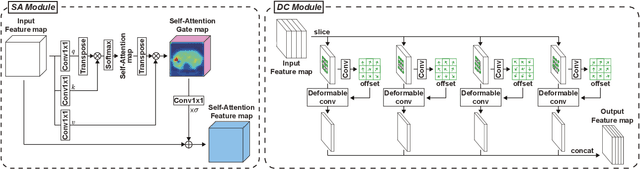
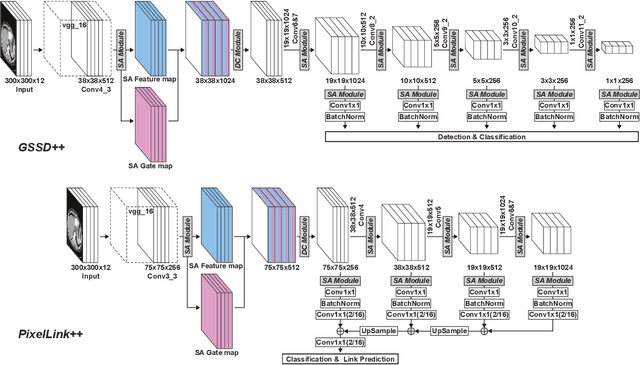
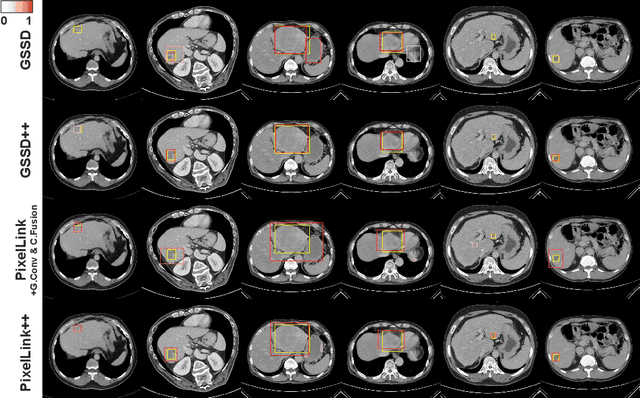
The computer-aided diagnosis of focal liver lesions (FLLs) can help improve workflow and enable correct diagnoses; FLL detection is the first step in such a computer-aided diagnosis. Despite the recent success of deep-learning-based approaches in detecting FLLs, current methods are not sufficiently robust for assessing misaligned multiphase data. By introducing an attention-guided multiphase alignment in feature space, this study presents a fully automated, end-to-end learning framework for detecting FLLs from multiphase computed tomography (CT) images. Our method is robust to misaligned multiphase images owing to its complete learning-based approach, which reduces the sensitivity of the model's performance to the quality of registration and enables a standalone deployment of the model in clinical practice. Evaluation on a large-scale dataset with 280 patients confirmed that our method outperformed previous state-of-the-art methods and significantly reduced the performance degradation for detecting FLLs using misaligned multiphase CT images. The robustness of the proposed method can enhance the clinical adoption of the deep-learning-based computer-aided detection system.
Street Crossing Aid Using Light-weight CNNs for the Visually Impaired
Sep 14, 2019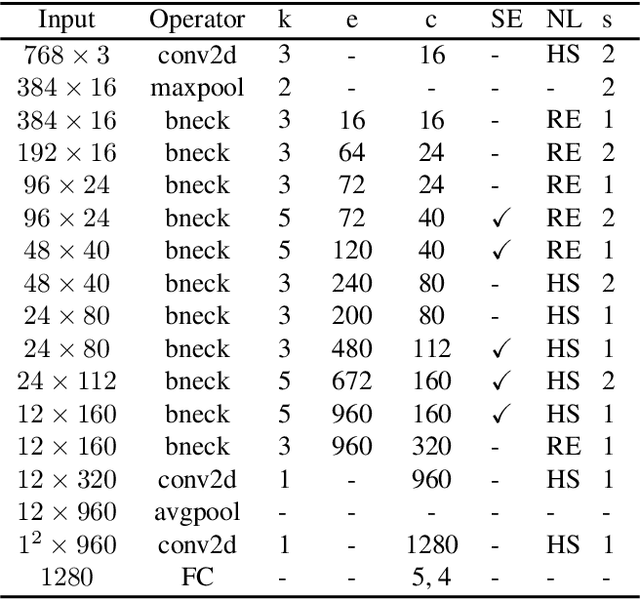

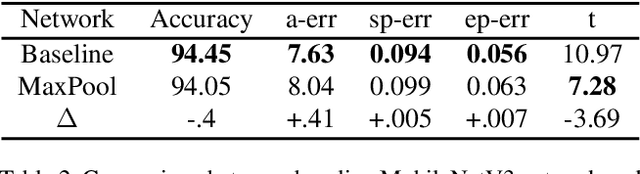

In this paper, we address an issue that the visually impaired commonly face while crossing intersections and propose a solution that takes form as a mobile application. The application utilizes a deep learning convolutional neural network model, LytNetV2, to output necessary information that the visually impaired may lack when without human companions or guide-dogs. A prototype of the application runs on iOS devices of versions 11 or above. It is designed for comprehensiveness, concision, accuracy, and computational efficiency through delivering the two most important pieces of information, pedestrian traffic light color and direction, required to cross the road in real-time. Furthermore, it is specifically aimed to support those facing financial burden as the solution takes the form of a free mobile application. Through the modification and utilization of key principles in MobileNetV3 such as depthwise seperable convolutions and squeeze-excite layers, the deep neural network model achieves a classification accuracy of 96% and average angle error of 6.15 degrees, while running at a frame rate of 16.34 frames per second. Additionally, the model is trained as an image classifier, allowing for a faster and more accurate model. The network is able to outperform other methods such as object detection and non-deep learning algorithms in both accuracy and thoroughness. The information is delivered through both auditory signals and vibrations, and it has been tested on seven visually impaired and has received above satisfactory responses.
Liver Lesion Detection from Weakly-labeled Multi-phase CT Volumes with a Grouped Single Shot MultiBox Detector
Jul 02, 2018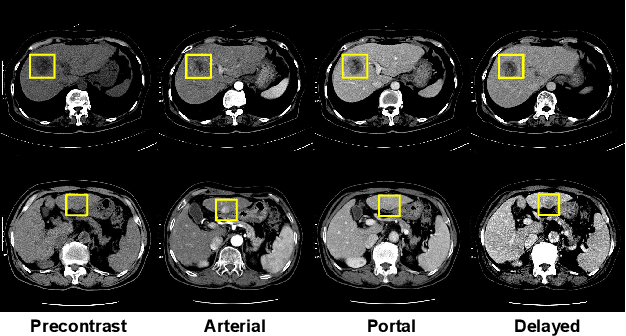
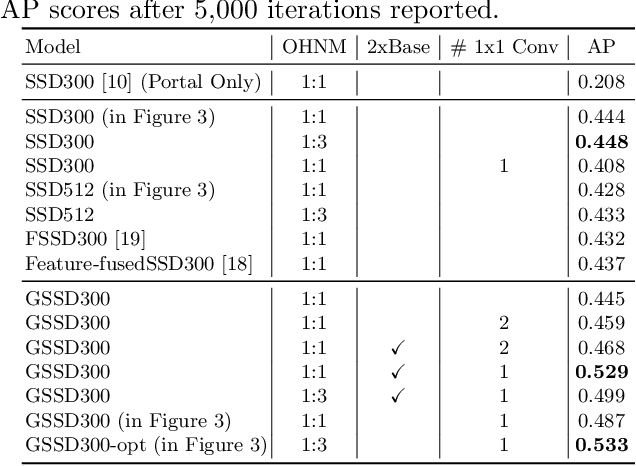
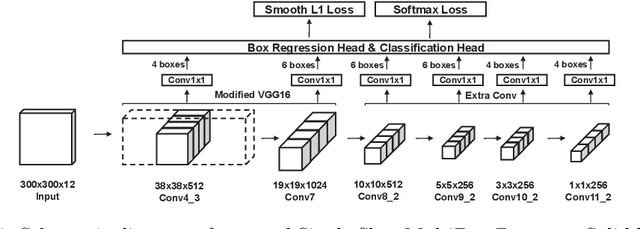
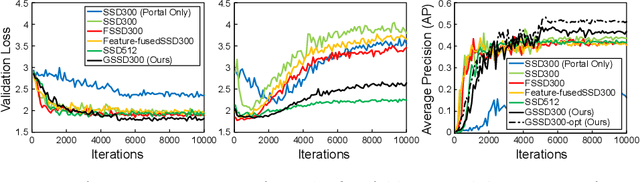
We present a focal liver lesion detection model leveraged by custom-designed multi-phase computed tomography (CT) volumes, which reflects real-world clinical lesion detection practice using a Single Shot MultiBox Detector (SSD). We show that grouped convolutions effectively harness richer information of the multi-phase data for the object detection model, while a naive application of SSD suffers from a generalization gap. We trained and evaluated the modified SSD model and recently proposed variants with our CT dataset of 64 subjects by five-fold cross validation. Our model achieved a 53.3% average precision score and ran in under three seconds per volume, outperforming the original model and state-of-the-art variants. Results show that the one-stage object detection model is a practical solution, which runs in near real-time and can learn an unbiased feature representation from a large-volume real-world detection dataset, which requires less tedious and time consuming construction of the weak phase-level bounding box labels.