 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Prediction of Future Behavioral Strategy from Process Traces
May 28, 2026Adaptive systems often need to make task-specific decisions about people from limited evidence: a tutor may need to anticipate how a learner will approach a new problem, a game may need to adapt when a player enters a new level, and a human-AI system may need to infer whether a partner will persist with a plan or switch goals. These decisions depend on person-level tendencies that shape how people solve related tasks, but such tendencies are difficult to infer from standard behavioral evidence. One approach is to use aggregate outcome summaries, such as scores, completion rates, or productivity; these summaries are compact and available across tasks, but can collapse distinct behavioral processes into similar outcomes. Another approach is to use process-level traces, which record how behavior unfolds; however, process modeling within one task can entangle stable person-level tendencies with task-specific layout and affordances. In this work, we study early cross-task behavioral inference: whether partial source-task process traces can reveal transferable person-level structure that predicts strategy in a held-out target task. We introduce a Process-Level Latent Variable Model (PLVM), which encodes task-specific traces and fuses them into a shared person-level latent representation for cross-task prediction. In PowerWash Simulator, a naturalistic telemetry dataset of human gameplay, PLVM uses partial traces from two cleaning tasks to predict locally persistent Zone Planner behavior versus frequent Zone Hopper behavior in the held-out Fire Station level. Controlled simulations with known latent types show that cross-task fusion helps when source tasks reveal complementary dimensions of a shared latent process. These results suggest that process-level cross-task modeling can support early prediction of target-task strategy when observing sufficient target-task behavior is impractical.
From Fallback to Frontline: When Can LLMs be Superior Annotators of Human Perspectives?
Apr 20, 2026Although large language models (LLMs) are increasingly used as annotators at scale, they are typically treated as a pragmatic fallback rather than a faithful estimator of human perspectives. This work challenges that presumption. By framing perspective-taking as the estimation of a latent group-level judgment, we characterize the conditions under which modern LLMs can outperform human annotators, including in-group humans, when predicting aggregate subgroup opinions on subjective tasks, and show that these conditions are common in practice. This advantage arises from structural properties of LLMs as estimators, including low variance and reduced coupling between representation and processing biases, rather than any claim of lived experience. Our analysis identifies clear regimes where LLMs act as statistically superior frontline estimators, as well as principled limits where human judgment remains essential. These findings reposition LLMs from a cost-saving compromise to a principled tool for estimating collective human perspectives.
Improving Human Performance with Value-Aware Interventions: A Case Study in Chess
Apr 15, 2026AI systems are increasingly used to assist humans in sequential decision-making tasks, yet determining when and how an AI assistant should intervene remains a fundamental challenge. A potential baseline is to recommend the optimal action according to a strong model. However, such actions assume optimal follow-up actions, which human decision makers may fail to execute, potentially reducing overall performance. In this work, we propose and study value-aware interventions, motivated by a basic principle in reinforcement learning: under the Bellman equation, the optimal policy selects actions that maximize the immediate reward plus the value function. When a decision maker follows a suboptimal policy, this policy-value consistency no longer holds, creating discrepancies between the actions taken by the policy and those that maximize the immediate reward plus the value of the next state. We show that these policy-value inconsistencies naturally identify opportunities for intervention. We formalize this problem in a Markov decision process where an AI assistant may override human actions under an intervention budget. In the single-intervention regime, we show that the optimal strategy is to recommend the action that maximizes the human value function. For settings with multiple interventions, we propose a tractable approximation that prioritizes interventions based on the magnitude of the policy-value discrepancy. We evaluate these ideas in the domain of chess by learning models of humans from large-scale gameplay data. In simulation, our approach consistently outperforms interventions based on the strongest chess engine (Stockfish) in a wide range of settings. A within-subject human study with 20 players and 600 games further shows that our interventions significantly improve performance for low- and mid-skill players while matching expert-engine interventions for high-skill players.
Adaptive Recruitment Resource Allocation to Improve Cohort Representativeness in Participatory Biomedical Datasets
Aug 02, 2024Large participatory biomedical studies, studies that recruit individuals to join a dataset, are gaining popularity and investment, especially for analysis by modern AI methods. Because they purposively recruit participants, these studies are uniquely able to address a lack of historical representation, an issue that has affected many biomedical datasets. In this work, we define representativeness as the similarity to a target population distribution of a set of attributes and our goal is to mirror the U.S. population across distributions of age, gender, race, and ethnicity. Many participatory studies recruit at several institutions, so we introduce a computational approach to adaptively allocate recruitment resources among sites to improve representativeness. In simulated recruitment of 10,000-participant cohorts from medical centers in the STAR Clinical Research Network, we show that our approach yields a more representative cohort than existing baselines. Thus, we highlight the value of computational modeling in guiding recruitment efforts.
Dataset Representativeness and Downstream Task Fairness
Jun 28, 2024



Our society collects data on people for a wide range of applications, from building a census for policy evaluation to running meaningful clinical trials. To collect data, we typically sample individuals with the goal of accurately representing a population of interest. However, current sampling processes often collect data opportunistically from data sources, which can lead to datasets that are biased and not representative, i.e., the collected dataset does not accurately reflect the distribution of demographics of the true population. This is a concern because subgroups within the population can be under- or over-represented in a dataset, which may harm generalizability and lead to an unequal distribution of benefits and harms from downstream tasks that use such datasets (e.g., algorithmic bias in medical decision-making algorithms). In this paper, we assess the relationship between dataset representativeness and group-fairness of classifiers trained on that dataset. We demonstrate that there is a natural tension between dataset representativeness and classifier fairness; empirically we observe that training datasets with better representativeness can frequently result in classifiers with higher rates of unfairness. We provide some intuition as to why this occurs via a set of theoretical results in the case of univariate classifiers. We also find that over-sampling underrepresented groups can result in classifiers which exhibit greater bias to those groups. Lastly, we observe that fairness-aware sampling strategies (i.e., those which are specifically designed to select data with high downstream fairness) will often over-sample members of majority groups. These results demonstrate that the relationship between dataset representativeness and downstream classifier fairness is complex; balancing these two quantities requires special care from both model- and dataset-designers.
On the Utility of Accounting for Human Beliefs about AI Behavior in Human-AI Collaboration
Jun 10, 2024To enable effective human-AI collaboration, merely optimizing AI performance while ignoring humans is not sufficient. Recent research has demonstrated that designing AI agents to account for human behavior leads to improved performance in human-AI collaboration. However, a limitation of most existing approaches is their assumption that human behavior is static, irrespective of AI behavior. In reality, humans may adjust their action plans based on their observations of AI behavior. In this paper, we address this limitation by enabling a collaborative AI agent to consider the beliefs of its human partner, i.e., what the human partner thinks the AI agent is doing, and design its action plan to facilitate easier collaboration with its human partner. Specifically, we developed a model of human beliefs that accounts for how humans reason about the behavior of their AI partners. Based on this belief model, we then developed an AI agent that considers both human behavior and human beliefs in devising its strategy for working with humans. Through extensive real-world human-subject experiments, we demonstrated that our belief model more accurately predicts humans' beliefs about AI behavior. Moreover, we showed that our design of AI agents that accounts for human beliefs enhances performance in human-AI collaboration.
Data-Driven Goal Recognition Design for General Behavioral Agents
Apr 03, 2024Goal recognition design aims to make limited modifications to decision-making environments with the goal of making it easier to infer the goals of agents acting within those environments. Although various research efforts have been made in goal recognition design, existing approaches are computationally demanding and often assume that agents are (near-)optimal in their decision-making. To address these limitations, we introduce a data-driven approach to goal recognition design that can account for agents with general behavioral models. Following existing literature, we use worst-case distinctiveness ($\textit{wcd}$) as a measure of the difficulty in inferring the goal of an agent in a decision-making environment. Our approach begins by training a machine learning model to predict the $\textit{wcd}$ for a given environment and the agent behavior model. We then propose a gradient-based optimization framework that accommodates various constraints to optimize decision-making environments for enhanced goal recognition. Through extensive simulations, we demonstrate that our approach outperforms existing methods in reducing $\textit{wcd}$ and enhancing runtime efficiency in conventional setups, and it also adapts to scenarios not previously covered in the literature, such as those involving flexible budget constraints, more complex environments, and suboptimal agent behavior. Moreover, we have conducted human-subject experiments which confirm that our method can create environments that facilitate efficient goal recognition from real-world human decision-makers.
Performative Prediction with Bandit Feedback: Learning through Reparameterization
May 08, 2023

Performative prediction, as introduced by Perdomo et al. (2020), is a framework for studying social prediction in which the data distribution itself changes in response to the deployment of a model. Existing work on optimizing accuracy in this setting hinges on two assumptions that are easily violated in practice: that the performative risk is convex over the deployed model, and that the mapping from the model to the data distribution is known to the model designer in advance. In this paper, we initiate the study of tractable performative prediction problems that do not require these assumptions. To tackle this more challenging setting, we develop a two-level zeroth-order optimization algorithm, where one level aims to compute the distribution map, and the other level reparameterizes the performative prediction objective as a function of the induced data distribution. Under mild conditions, this reparameterization allows us to transform the non-convex objective into a convex one and achieve provable regret guarantees. In particular, we provide a regret bound that is sublinear in the total number of performative samples taken and only polynomial in the dimension of the model parameter.
Optimal Query Complexity of Secure Stochastic Convex Optimization
Apr 05, 2021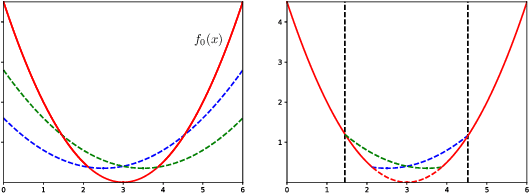
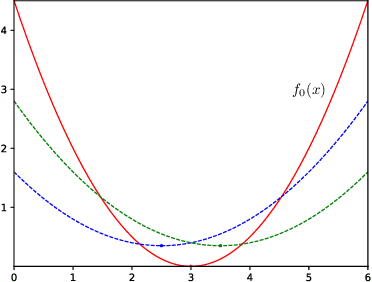
We study the secure stochastic convex optimization problem. A learner aims to learn the optimal point of a convex function through sequentially querying a (stochastic) gradient oracle. In the meantime, there exists an adversary who aims to free-ride and infer the learning outcome of the learner from observing the learner's queries. The adversary observes only the points of the queries but not the feedback from the oracle. The goal of the learner is to optimize the accuracy, i.e., obtaining an accurate estimate of the optimal point, while securing her privacy, i.e., making it difficult for the adversary to infer the optimal point. We formally quantify this tradeoff between learner's accuracy and privacy and characterize the lower and upper bounds on the learner's query complexity as a function of desired levels of accuracy and privacy. For the analysis of lower bounds, we provide a general template based on information theoretical analysis and then tailor the template to several families of problems, including stochastic convex optimization and (noisy) binary search. We also present a generic secure learning protocol that achieves the matching upper bound up to logarithmic factors.
Fair Bandit Learning with Delayed Impact of Actions
Feb 24, 2020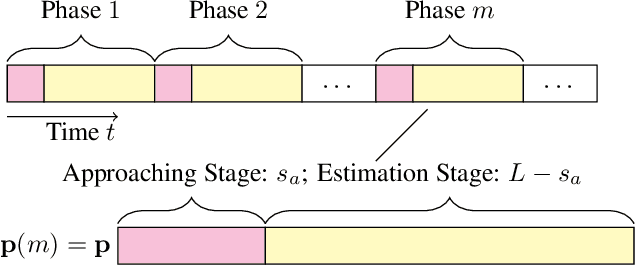
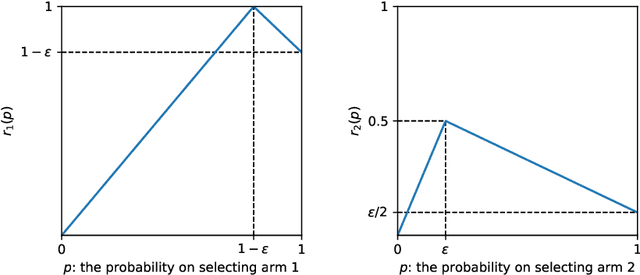
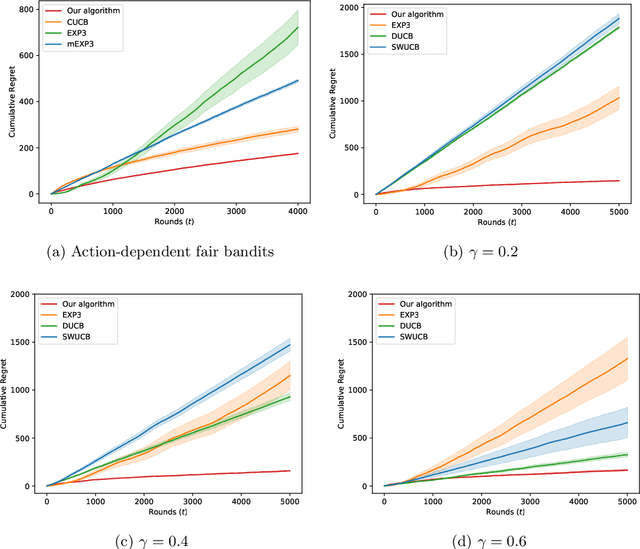
Algorithmic fairness has been studied mostly in a static setting where the implicit assumptions are that the frequencies of historically made decisions do not impact the problem structure in subsequent future. However, for example, the capability to pay back a loan for people in a certain group might depend on historically how frequently that group has been approved loan applications. If banks keep rejecting loan applications to people in a disadvantaged group, it could create a feedback loop and further damage the chance of getting loans for people in that group. This challenge has been noted in several recent works but is under-explored in a more generic sequential learning setting. In this paper, we formulate this delayed and long-term impact of actions within the context of multi-armed bandits (MAB). We generalize the classical bandit setting to encode the dependency of this action "bias" due to the history of the learning. Our goal is to learn to maximize the collected utilities over time while satisfying fairness constraints imposed over arms' utilities, which again depend on the decision they have received. We propose an algorithm that achieves a regret of $\tilde{\mathcal{O}}(KT^{2/3})$ and show a matching regret lower bound of $\Omega(KT^{2/3})$, where $K$ is the number of arms and $T$ denotes the learning horizon. Our results complement the bandit literature by adding techniques to deal with actions with long-term impacts and have implications in designing fair algorithms.