 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Bandit Learning with Delayed Impact of Actions
Paper and Code
Feb 24, 2020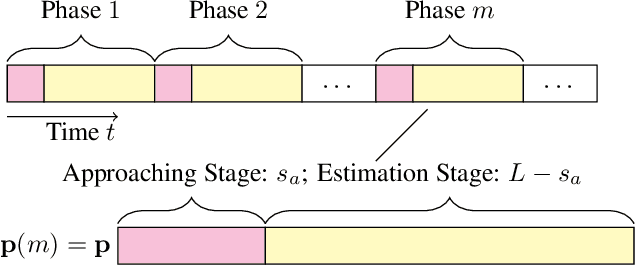
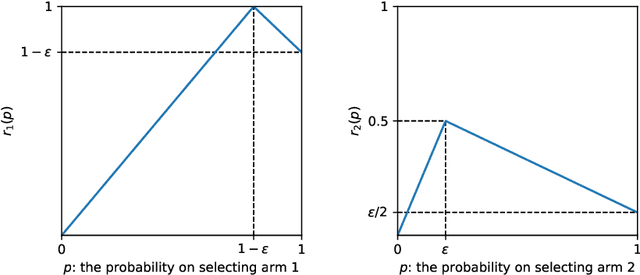
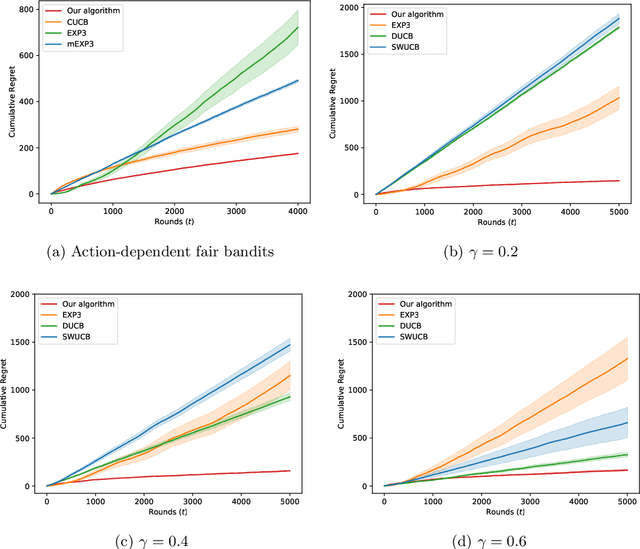
Algorithmic fairness has been studied mostly in a static setting where the implicit assumptions are that the frequencies of historically made decisions do not impact the problem structure in subsequent future. However, for example, the capability to pay back a loan for people in a certain group might depend on historically how frequently that group has been approved loan applications. If banks keep rejecting loan applications to people in a disadvantaged group, it could create a feedback loop and further damage the chance of getting loans for people in that group. This challenge has been noted in several recent works but is under-explored in a more generic sequential learning setting. In this paper, we formulate this delayed and long-term impact of actions within the context of multi-armed bandits (MAB). We generalize the classical bandit setting to encode the dependency of this action "bias" due to the history of the learning. Our goal is to learn to maximize the collected utilities over time while satisfying fairness constraints imposed over arms' utilities, which again depend on the decision they have received. We propose an algorithm that achieves a regret of $\tilde{\mathcal{O}}(KT^{2/3})$ and show a matching regret lower bound of $\Omega(KT^{2/3})$, where $K$ is the number of arms and $T$ denotes the learning horizon. Our results complement the bandit literature by adding techniques to deal with actions with long-term impacts and have implications in designing fair algorithms.