Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA K-fold Method for Baseline Estimation in Policy Gradient Algorithms
Paper and Code
Jan 03, 2017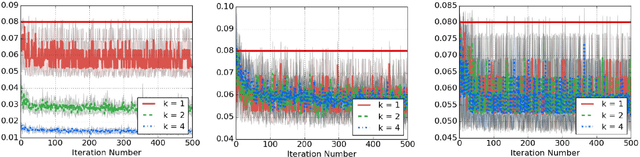
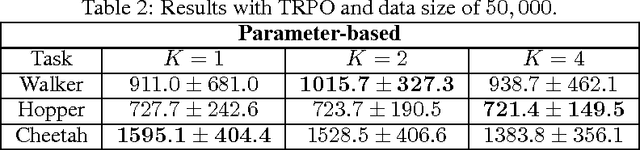
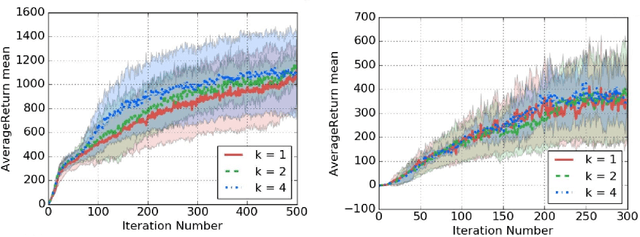
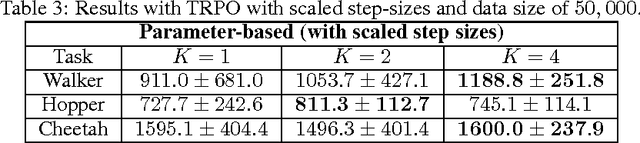
The high variance issue in unbiased policy-gradient methods such as VPG and REINFORCE is typically mitigated by adding a baseline. However, the baseline fitting itself suffers from the underfitting or the overfitting problem. In this paper, we develop a K-fold method for baseline estimation in policy gradient algorithms. The parameter K is the baseline estimation hyperparameter that can adjust the bias-variance trade-off in the baseline estimates. We demonstrate the usefulness of our approach via two state-of-the-art policy gradient algorithms on three MuJoCo locomotive control tasks.
View paper on