 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Objective Design Optimization of Non Pneumatic Passenger Car Tires Using Finite Element Modeling, Machine Learning, and Particle swarm Optimization and Bayesian Optimization Algorithms
Feb 04, 2026Non Pneumatic tires offer a promising alternative to pneumatic tires. However, their discontinuous spoke structures present challenges in stiffness tuning, durability, and high speed vibration. This study introduces an integrated generative design and machine learning driven framework to optimize UPTIS type spoke geometries for passenger vehicles. Upper and lower spoke profiles were parameterized using high order polynomial representations, enabling the creation of approximately 250 generative designs through PCHIP based geometric variation. Machine learning models like KRR for stiffness and XGBoost for durability and vibration achieved strong predictive accuracy, reducing the reliance on computationally intensive FEM simulations. Optimization using Particle Swarm Optimization and Bayesian Optimization further enabled extensive performance refinement. The resulting designs demonstrate 53% stiffness tunability, up to 50% durability improvement, and 43% reduction in vibration compared to the baseline. PSO provided fast, targeted convergence, while Bayesian Optimization effectively explored multi objective tradeoffs. Overall, the proposed framework enables systematic development of high performance, next generation UPTIS spoke structures.
AutoChemSchematic AI: A Closed-Loop, Physics-Aware Agentic Framework for Auto-Generating Chemical Process and Instrumentation Diagrams
May 30, 2025Recent advancements in generative AI have accelerated the discovery of novel chemicals and materials; however, transitioning these discoveries to industrial-scale production remains a critical bottleneck, as it requires the development of entirely new chemical manufacturing processes. Current AI methods cannot auto-generate PFDs or PIDs, despite their critical role in scaling chemical processes, while adhering to engineering constraints. We present a closed loop, physics aware framework for the automated generation of industrially viable PFDs and PIDs. The framework integrates domain specialized small scale language models (SLMs) (trained for chemical process QA tasks) with first principles simulation, leveraging three key components: (1) a hierarchical knowledge graph of process flow and instrumentation descriptions for 1,020+ chemicals, (2) a multi-stage training pipeline that fine tunes domain specialized SLMs on synthetic datasets via Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Retrieval-Augmented Instruction Tuning (RAIT), and (3) DWSIM based simulator in the loop validation to ensure feasibility. To improve both runtime efficiency and model compactness, the framework incorporates advanced inference time optimizations including FlashAttention, Lookahead Decoding, PagedAttention with KV-cache quantization, and Test Time Inference Scaling and independently applies structural pruning techniques (width and depth) guided by importance heuristics to reduce model size with minimal accuracy loss. Experiments demonstrate that the framework generates simulator-validated process descriptions with high fidelity, outperforms baseline methods in correctness, and generalizes to unseen chemicals. By bridging AI-driven design with industrial-scale feasibility, this work significantly reduces R&D timelines from lab discovery to plant deployment.
Scaling Test-Time Inference with Policy-Optimized, Dynamic Retrieval-Augmented Generation via KV Caching and Decoding
Apr 03, 2025



We present a comprehensive framework for enhancing Retrieval-Augmented Generation (RAG) systems through dynamic retrieval strategies and reinforcement fine-tuning. This approach significantly improves large language models on knowledge-intensive tasks, including opendomain question answering and complex reasoning. Our framework integrates two complementary techniques: Policy-Optimized RetrievalAugmented Generation (PORAG), which optimizes the use of retrieved information, and Adaptive Token-Layer Attention Scoring (ATLAS), which dynamically determines retrieval timing and content based on contextual needs. Together, these techniques enhance both the utilization and relevance of retrieved content, improving factual accuracy and response quality. Designed as a lightweight solution compatible with any Transformer-based LLM without requiring additional training, our framework excels in knowledge-intensive tasks, boosting output accuracy in RAG settings. We further propose CRITIC, a novel method to selectively compress key-value caches by token importance, mitigating memory bottlenecks in long-context applications. The framework also incorporates test-time scaling techniques to dynamically balance reasoning depth and computational resources, alongside optimized decoding strategies for faster inference. Experiments on benchmark datasets show that our framework reduces hallucinations, strengthens domain-specific reasoning, and achieves significant efficiency and scalability gains over traditional RAG systems. This integrated approach advances the development of robust, efficient, and scalable RAG systems across diverse applications.
Agentic Multimodal AI for Hyperpersonalized B2B and B2C Advertising in Competitive Markets: An AI-Driven Competitive Advertising Framework
Apr 01, 2025
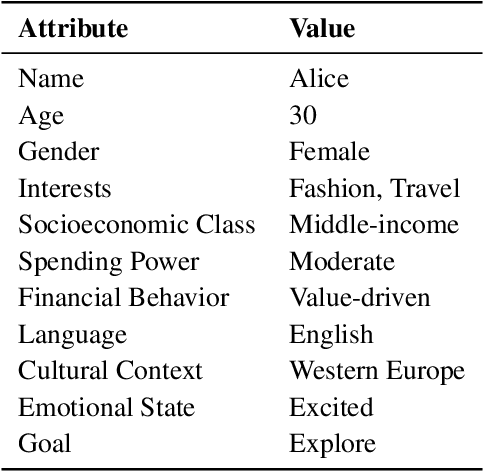
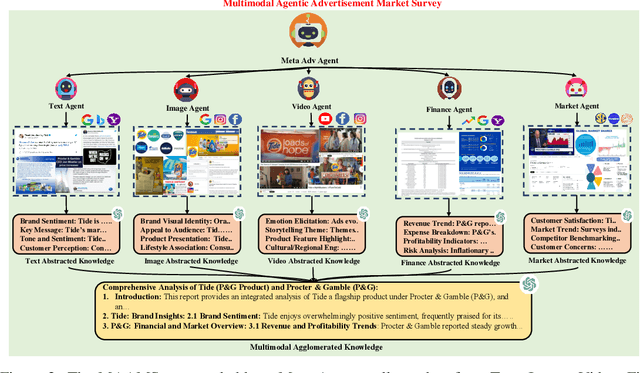

The growing use of foundation models (FMs) in real-world applications demands adaptive, reliable, and efficient strategies for dynamic markets. In the chemical industry, AI-discovered materials drive innovation, but commercial success hinges on market adoption, requiring FM-driven advertising frameworks that operate in-the-wild. We present a multilingual, multimodal AI framework for autonomous, hyper-personalized advertising in B2B and B2C markets. By integrating retrieval-augmented generation (RAG), multimodal reasoning, and adaptive persona-based targeting, our system generates culturally relevant, market-aware ads tailored to shifting consumer behaviors and competition. Validation combines real-world product experiments with a Simulated Humanistic Colony of Agents to model consumer personas, optimize strategies at scale, and ensure privacy compliance. Synthetic experiments mirror real-world scenarios, enabling cost-effective testing of ad strategies without risky A/B tests. Combining structured retrieval-augmented reasoning with in-context learning (ICL), the framework boosts engagement, prevents market cannibalization, and maximizes ROAS. This work bridges AI-driven innovation and market adoption, advancing multimodal FM deployment for high-stakes decision-making in commercial marketing.
Two-level Solar Irradiance Clustering with Season Identification: A Comparative Analysis
Jan 17, 2025



Solar irradiance clustering can enhance solar power capacity planning and help improve forecasting models by identifying similar irradiance patterns influenced by seasonal and weather changes. In this study, we adopt an efficient two-level clustering approach to automatically identify seasons using the clear sky irradiance in first level and subsequently to identify daily cloud level as clear, cloudy and partly cloudy within each season in second level. In the second level of clustering, three methods are compared, namely, Daily Irradiance Index (DII or $\beta$), Euclidean Distance (ED), and Dynamic Time Warping (DTW) distance. The DII is computed as the ratio of time integral of measured irradiance to time integral of the clear sky irradiance. The identified clusters were compared quantitatively using established clustering metrics and qualitatively by comparing the mean irradiance profiles. The results clearly establish the superiority of the $\beta$-based clustering approach as the leader, setting a new benchmark for solar irradiance clustering studies. Moreover, $\beta$-based clustering remains effective even for annual data unlike the time-series methods which suffer significant performance degradation. Interestingly, contrary to expectations, ED-based clustering outperforms the more compute-intensive DTW distance-based clustering. The method has been rigorously validated using data from two distinct US locations, demonstrating robust scalability for larger datasets and potential applicability for other locations.
Accelerating Manufacturing Scale-Up from Material Discovery Using Agentic Web Navigation and Retrieval-Augmented AI for Process Engineering Schematics Design
Dec 08, 2024



Process Flow Diagrams (PFDs) and Process and Instrumentation Diagrams (PIDs) are critical tools for industrial process design, control, and safety. However, the generation of precise and regulation-compliant diagrams remains a significant challenge, particularly in scaling breakthroughs from material discovery to industrial production in an era of automation and digitalization. This paper introduces an autonomous agentic framework to address these challenges through a twostage approach involving knowledge acquisition and generation. The framework integrates specialized sub-agents for retrieving and synthesizing multimodal data from publicly available online sources and constructs ontological knowledge graphs using a Graph Retrieval-Augmented Generation (Graph RAG) paradigm. These capabilities enable the automation of diagram generation and open-domain question answering (ODQA) tasks with high contextual accuracy. Extensive empirical experiments demonstrate the frameworks ability to deliver regulation-compliant diagrams with minimal expert intervention, highlighting its practical utility for industrial applications.
Parameter-Efficient Quantized Mixture-of-Experts Meets Vision-Language Instruction Tuning for Semiconductor Electron Micrograph Analysis
Aug 27, 2024



Semiconductors, crucial to modern electronics, are generally under-researched in foundational models. It highlights the need for research to enhance the semiconductor device technology portfolio and aid in high-end device fabrication. In this paper, we introduce sLAVA, a small-scale vision-language assistant tailored for semiconductor manufacturing, with a focus on electron microscopy image analysis. It addresses challenges of data scarcity and acquiring high-quality, expert-annotated data. We employ a teacher-student paradigm, using a foundational vision language model like GPT-4 as a teacher to create instruction-following multimodal data for customizing the student model, sLAVA, for electron microscopic image analysis tasks on consumer hardware with limited budgets. Our approach allows enterprises to further fine-tune the proposed framework with their proprietary data securely within their own infrastructure, protecting intellectual property. Rigorous experiments validate that our framework surpasses traditional methods, handles data shifts, and enables high-throughput screening.
Cross-Modal Learning for Chemistry Property Prediction: Large Language Models Meet Graph Machine Learning
Aug 27, 2024



In the field of chemistry, the objective is to create novel molecules with desired properties, facilitating accurate property predictions for applications such as material design and drug screening. However, existing graph deep learning methods face limitations that curb their expressive power. To address this, we explore the integration of vast molecular domain knowledge from Large Language Models (LLMs) with the complementary strengths of Graph Neural Networks (GNNs) to enhance performance in property prediction tasks. We introduce a Multi-Modal Fusion (MMF) framework that synergistically harnesses the analytical prowess of GNNs and the linguistic generative and predictive abilities of LLMs, thereby improving accuracy and robustness in predicting molecular properties. Our framework combines the effectiveness of GNNs in modeling graph-structured data with the zero-shot and few-shot learning capabilities of LLMs, enabling improved predictions while reducing the risk of overfitting. Furthermore, our approach effectively addresses distributional shifts, a common challenge in real-world applications, and showcases the efficacy of learning cross-modal representations, surpassing state-of-the-art baselines on benchmark datasets for property prediction tasks.
Reprogramming Foundational Large Language Models(LLMs) for Enterprise Adoption for Spatio-Temporal Forecasting Applications: Unveiling a New Era in Copilot-Guided Cross-Modal Time Series Representation Learning
Aug 26, 2024



Spatio-temporal forecasting plays a crucial role in various sectors such as transportation systems, logistics, and supply chain management. However, existing methods are limited by their ability to handle large, complex datasets. To overcome this limitation, we introduce a hybrid approach that combines the strengths of open-source large and small-scale language models (LLMs and LMs) with traditional forecasting methods. We augment traditional methods with dynamic prompting and a grouped-query, multi-head attention mechanism to more effectively capture both intra-series and inter-series dependencies in evolving nonlinear time series data. In addition, we facilitate on-premises customization by fine-tuning smaller open-source LMs for time series trend analysis utilizing descriptions generated by open-source large LMs on consumer-grade hardware using Low-Rank Adaptation with Activation Memory Reduction (LoRA-AMR) technique to reduce computational overhead and activation storage memory demands while preserving inference latency. We combine language model processing for time series trend analysis with traditional time series representation learning method for cross-modal integration, achieving robust and accurate forecasts. The framework effectiveness is demonstrated through extensive experiments on various real-world datasets, outperforming existing methods by significant margins in terms of forecast accuracy.
Hierarchical Network Fusion for Multi-Modal Electron Micrograph Representation Learning with Foundational Large Language Models
Aug 24, 2024Characterizing materials with electron micrographs is a crucial task in fields such as semiconductors and quantum materials. The complex hierarchical structure of micrographs often poses challenges for traditional classification methods. In this study, we propose an innovative backbone architecture for analyzing electron micrographs. We create multi-modal representations of the micrographs by tokenizing them into patch sequences and, additionally, representing them as vision graphs, commonly referred to as patch attributed graphs. We introduce the Hierarchical Network Fusion (HNF), a multi-layered network structure architecture that facilitates information exchange between the multi-modal representations and knowledge integration across different patch resolutions. Furthermore, we leverage large language models (LLMs) to generate detailed technical descriptions of nanomaterials as auxiliary information to assist in the downstream task. We utilize a cross-modal attention mechanism for knowledge fusion across cross-domain representations(both image-based and linguistic insights) to predict the nanomaterial category. This multi-faceted approach promises a more comprehensive and accurate representation and classification of micrographs for nanomaterial identification. Our framework outperforms traditional methods, overcoming challenges posed by distributional shifts, and facilitating high-throughput screening.