 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI Understand What We Cannot Say? Measuring Multilevel Alignment Through Abortion Stigma Across Cognitive, Interpersonal, and Structural Levels
Dec 22, 2025



As large language models increasingly mediate stigmatized health decisions, their capacity to genuinely understand complex psychological and physiological phenomena remains poorly evaluated. Can AI understand what we cannot say? We investigate whether LLMs coherently represent abortion stigma across the cognitive, interpersonal, and structural levels where it operates. We systematically tested 627 demographically diverse personas across five leading LLMs using the validated Individual Level Abortion Stigma Scale (ILAS). Our multilevel analysis examined whether models coherently represent stigma at the cognitive level (self-judgment), interpersonal level (worries about judgment and isolation), and structural level (community condemnation and disclosure patterns), as well as overall stigma. Models fail tests of genuine understanding across all levels. They overestimate interpersonal stigma while underestimating cognitive stigma, assume uniform community condemnation, introduce demographic biases absent from human validation data, miss the empirically validated stigma-secrecy relationship, and contradict themselves within theoretical constructs. These patterns reveal that current alignment approaches ensure appropriate language but not coherent multilevel understanding. This work provides empirical evidence that current LLMs lack coherent multilevel understanding of psychological and physiological constructs. AI safety in high-stakes contexts demands new approaches to design (multilevel coherence), evaluation (continuous auditing), governance and regulation (mandatory audits, accountability, deployment restrictions), and AI literacy in domains where understanding what people cannot say determines whether support helps or harms.
Commentary Generation for Soccer Highlights
Aug 11, 2025Automated soccer commentary generation has evolved from template-based systems to advanced neural architectures, aiming to produce real-time descriptions of sports events. While frameworks like SoccerNet-Caption laid foundational work, their inability to achieve fine-grained alignment between video content and commentary remains a significant challenge. Recent efforts such as MatchTime, with its MatchVoice model, address this issue through coarse and fine-grained alignment techniques, achieving improved temporal synchronization. In this paper, we extend MatchVoice to commentary generation for soccer highlights using the GOAL dataset, which emphasizes short clips over entire games. We conduct extensive experiments to reproduce the original MatchTime results and evaluate our setup, highlighting the impact of different training configurations and hardware limitations. Furthermore, we explore the effect of varying window sizes on zero-shot performance. While MatchVoice exhibits promising generalization capabilities, our findings suggest the need for integrating techniques from broader video-language domains to further enhance performance. Our code is available at https://github.com/chidaksh/SoccerCommentary.
Parameter-Efficient Quantized Mixture-of-Experts Meets Vision-Language Instruction Tuning for Semiconductor Electron Micrograph Analysis
Aug 27, 2024



Semiconductors, crucial to modern electronics, are generally under-researched in foundational models. It highlights the need for research to enhance the semiconductor device technology portfolio and aid in high-end device fabrication. In this paper, we introduce sLAVA, a small-scale vision-language assistant tailored for semiconductor manufacturing, with a focus on electron microscopy image analysis. It addresses challenges of data scarcity and acquiring high-quality, expert-annotated data. We employ a teacher-student paradigm, using a foundational vision language model like GPT-4 as a teacher to create instruction-following multimodal data for customizing the student model, sLAVA, for electron microscopic image analysis tasks on consumer hardware with limited budgets. Our approach allows enterprises to further fine-tune the proposed framework with their proprietary data securely within their own infrastructure, protecting intellectual property. Rigorous experiments validate that our framework surpasses traditional methods, handles data shifts, and enables high-throughput screening.
Reprogramming Foundational Large Language Models(LLMs) for Enterprise Adoption for Spatio-Temporal Forecasting Applications: Unveiling a New Era in Copilot-Guided Cross-Modal Time Series Representation Learning
Aug 26, 2024



Spatio-temporal forecasting plays a crucial role in various sectors such as transportation systems, logistics, and supply chain management. However, existing methods are limited by their ability to handle large, complex datasets. To overcome this limitation, we introduce a hybrid approach that combines the strengths of open-source large and small-scale language models (LLMs and LMs) with traditional forecasting methods. We augment traditional methods with dynamic prompting and a grouped-query, multi-head attention mechanism to more effectively capture both intra-series and inter-series dependencies in evolving nonlinear time series data. In addition, we facilitate on-premises customization by fine-tuning smaller open-source LMs for time series trend analysis utilizing descriptions generated by open-source large LMs on consumer-grade hardware using Low-Rank Adaptation with Activation Memory Reduction (LoRA-AMR) technique to reduce computational overhead and activation storage memory demands while preserving inference latency. We combine language model processing for time series trend analysis with traditional time series representation learning method for cross-modal integration, achieving robust and accurate forecasts. The framework effectiveness is demonstrated through extensive experiments on various real-world datasets, outperforming existing methods by significant margins in terms of forecast accuracy.
Preliminary Investigations of a Multi-Faceted Robust and Synergistic Approach in Semiconductor Electron Micrograph Analysis: Integrating Vision Transformers with Large Language and Multimodal Models
Aug 24, 2024

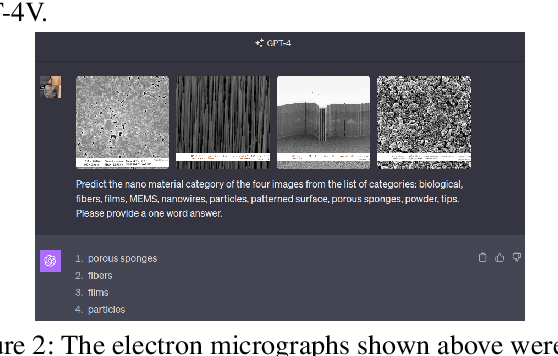

Characterizing materials using electron micrographs is crucial in areas such as semiconductors and quantum materials. Traditional classification methods falter due to the intricatestructures of these micrographs. This study introduces an innovative architecture that leverages the generative capabilities of zero-shot prompting in Large Language Models (LLMs) such as GPT-4(language only), the predictive ability of few-shot (in-context) learning in Large Multimodal Models (LMMs) such as GPT-4(V)ision, and fuses knowledge across image based and linguistic insights for accurate nanomaterial category prediction. This comprehensive approach aims to provide a robust solution for the automated nanomaterial identification task in semiconductor manufacturing, blending performance, efficiency, and interpretability. Our method surpasses conventional approaches, offering precise nanomaterial identification and facilitating high-throughput screening.
Advancing Enterprise Spatio-Temporal Forecasting Applications: Data Mining Meets Instruction Tuning of Language Models For Multi-modal Time Series Analysis in Low-Resource Settings
Aug 24, 2024



Spatio-temporal forecasting is crucial in transportation, logistics, and supply chain management. However, current methods struggle with large, complex datasets. We propose a dynamic, multi-modal approach that integrates the strengths of traditional forecasting methods and instruction tuning of small language models for time series trend analysis. This approach utilizes a mixture of experts (MoE) architecture with parameter-efficient fine-tuning (PEFT) methods, tailored for consumer hardware to scale up AI solutions in low resource settings while balancing performance and latency tradeoffs. Additionally, our approach leverages related past experiences for similar input time series to efficiently handle both intra-series and inter-series dependencies of non-stationary data with a time-then-space modeling approach, using grouped-query attention, while mitigating the limitations of traditional forecasting techniques in handling distributional shifts. Our approach models predictive uncertainty to improve decision-making. Our framework enables on-premises customization with reduced computational and memory demands, while maintaining inference speed and data privacy/security. Extensive experiments on various real-world datasets demonstrate that our framework provides robust and accurate forecasts, significantly outperforming existing methods.
Foundational Model for Electron Micrograph Analysis: Instruction-Tuning Small-Scale Language-and-Vision Assistant for Enterprise Adoption
Aug 23, 2024



Semiconductor imaging and analysis are critical yet understudied in deep learning, limiting our ability for precise control and optimization in semiconductor manufacturing. We introduce a small-scale multimodal framework for analyzing semiconductor electron microscopy images (MAEMI) through vision-language instruction tuning. We generate a customized instruction-following dataset using large multimodal models on microscopic image analysis. We perform knowledge transfer from larger to smaller models through knowledge distillation, resulting in improved accuracy of smaller models on visual question answering (VQA) tasks. This approach eliminates the need for expensive, human expert-annotated datasets for microscopic image analysis tasks. Enterprises can further finetune MAEMI on their intellectual data, enhancing privacy and performance on low-cost consumer hardware. Our experiments show that MAEMI outperforms traditional methods, adapts to data distribution shifts, and supports high-throughput screening.
RESTORE: Graph Embedding Assessment Through Reconstruction
Sep 05, 2023Following the success of Word2Vec embeddings, graph embeddings (GEs) have gained substantial traction. GEs are commonly generated and evaluated extrinsically on downstream applications, but intrinsic evaluations of the original graph properties in terms of topological structure and semantic information have been lacking. Understanding these will help identify the deficiency of the various families of GE methods when vectorizing graphs in terms of preserving the relevant knowledge or learning incorrect knowledge. To address this, we propose RESTORE, a framework for intrinsic GEs assessment through graph reconstruction. We show that reconstructing the original graph from the underlying GEs yields insights into the relative amount of information preserved in a given vector form. We first introduce the graph reconstruction task. We generate GEs from three GE families based on factorization methods, random walks, and deep learning (with representative algorithms from each family) on the CommonSense Knowledge Graph (CSKG). We analyze their effectiveness in preserving the (a) topological structure of node-level graph reconstruction with an increasing number of hops and (b) semantic information on various word semantic and analogy tests. Our evaluations show deep learning-based GE algorithm (SDNE) is overall better at preserving (a) with a mean average precision (mAP) of 0.54 and 0.35 for 2 and 3-hop reconstruction respectively, while the factorization-based algorithm (HOPE) is better at encapsulating (b) with an average Euclidean distance of 0.14, 0.17, and 0.11 for 1, 2, and 3-hop reconstruction respectively. The modest performance of these GEs leaves room for further research avenues on better graph representation learning.