 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Quantized Mixture-of-Experts Meets Vision-Language Instruction Tuning for Semiconductor Electron Micrograph Analysis
Aug 27, 2024



Semiconductors, crucial to modern electronics, are generally under-researched in foundational models. It highlights the need for research to enhance the semiconductor device technology portfolio and aid in high-end device fabrication. In this paper, we introduce sLAVA, a small-scale vision-language assistant tailored for semiconductor manufacturing, with a focus on electron microscopy image analysis. It addresses challenges of data scarcity and acquiring high-quality, expert-annotated data. We employ a teacher-student paradigm, using a foundational vision language model like GPT-4 as a teacher to create instruction-following multimodal data for customizing the student model, sLAVA, for electron microscopic image analysis tasks on consumer hardware with limited budgets. Our approach allows enterprises to further fine-tune the proposed framework with their proprietary data securely within their own infrastructure, protecting intellectual property. Rigorous experiments validate that our framework surpasses traditional methods, handles data shifts, and enables high-throughput screening.
Reprogramming Foundational Large Language Models(LLMs) for Enterprise Adoption for Spatio-Temporal Forecasting Applications: Unveiling a New Era in Copilot-Guided Cross-Modal Time Series Representation Learning
Aug 26, 2024



Spatio-temporal forecasting plays a crucial role in various sectors such as transportation systems, logistics, and supply chain management. However, existing methods are limited by their ability to handle large, complex datasets. To overcome this limitation, we introduce a hybrid approach that combines the strengths of open-source large and small-scale language models (LLMs and LMs) with traditional forecasting methods. We augment traditional methods with dynamic prompting and a grouped-query, multi-head attention mechanism to more effectively capture both intra-series and inter-series dependencies in evolving nonlinear time series data. In addition, we facilitate on-premises customization by fine-tuning smaller open-source LMs for time series trend analysis utilizing descriptions generated by open-source large LMs on consumer-grade hardware using Low-Rank Adaptation with Activation Memory Reduction (LoRA-AMR) technique to reduce computational overhead and activation storage memory demands while preserving inference latency. We combine language model processing for time series trend analysis with traditional time series representation learning method for cross-modal integration, achieving robust and accurate forecasts. The framework effectiveness is demonstrated through extensive experiments on various real-world datasets, outperforming existing methods by significant margins in terms of forecast accuracy.
Hierarchical Network Fusion for Multi-Modal Electron Micrograph Representation Learning with Foundational Large Language Models
Aug 24, 2024Characterizing materials with electron micrographs is a crucial task in fields such as semiconductors and quantum materials. The complex hierarchical structure of micrographs often poses challenges for traditional classification methods. In this study, we propose an innovative backbone architecture for analyzing electron micrographs. We create multi-modal representations of the micrographs by tokenizing them into patch sequences and, additionally, representing them as vision graphs, commonly referred to as patch attributed graphs. We introduce the Hierarchical Network Fusion (HNF), a multi-layered network structure architecture that facilitates information exchange between the multi-modal representations and knowledge integration across different patch resolutions. Furthermore, we leverage large language models (LLMs) to generate detailed technical descriptions of nanomaterials as auxiliary information to assist in the downstream task. We utilize a cross-modal attention mechanism for knowledge fusion across cross-domain representations(both image-based and linguistic insights) to predict the nanomaterial category. This multi-faceted approach promises a more comprehensive and accurate representation and classification of micrographs for nanomaterial identification. Our framework outperforms traditional methods, overcoming challenges posed by distributional shifts, and facilitating high-throughput screening.
Advancing Enterprise Spatio-Temporal Forecasting Applications: Data Mining Meets Instruction Tuning of Language Models For Multi-modal Time Series Analysis in Low-Resource Settings
Aug 24, 2024



Spatio-temporal forecasting is crucial in transportation, logistics, and supply chain management. However, current methods struggle with large, complex datasets. We propose a dynamic, multi-modal approach that integrates the strengths of traditional forecasting methods and instruction tuning of small language models for time series trend analysis. This approach utilizes a mixture of experts (MoE) architecture with parameter-efficient fine-tuning (PEFT) methods, tailored for consumer hardware to scale up AI solutions in low resource settings while balancing performance and latency tradeoffs. Additionally, our approach leverages related past experiences for similar input time series to efficiently handle both intra-series and inter-series dependencies of non-stationary data with a time-then-space modeling approach, using grouped-query attention, while mitigating the limitations of traditional forecasting techniques in handling distributional shifts. Our approach models predictive uncertainty to improve decision-making. Our framework enables on-premises customization with reduced computational and memory demands, while maintaining inference speed and data privacy/security. Extensive experiments on various real-world datasets demonstrate that our framework provides robust and accurate forecasts, significantly outperforming existing methods.
Preliminary Investigations of a Multi-Faceted Robust and Synergistic Approach in Semiconductor Electron Micrograph Analysis: Integrating Vision Transformers with Large Language and Multimodal Models
Aug 24, 2024

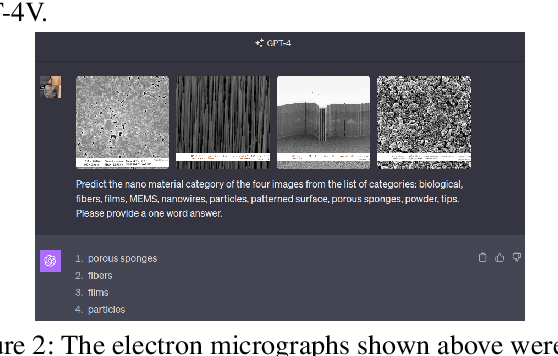

Characterizing materials using electron micrographs is crucial in areas such as semiconductors and quantum materials. Traditional classification methods falter due to the intricatestructures of these micrographs. This study introduces an innovative architecture that leverages the generative capabilities of zero-shot prompting in Large Language Models (LLMs) such as GPT-4(language only), the predictive ability of few-shot (in-context) learning in Large Multimodal Models (LMMs) such as GPT-4(V)ision, and fuses knowledge across image based and linguistic insights for accurate nanomaterial category prediction. This comprehensive approach aims to provide a robust solution for the automated nanomaterial identification task in semiconductor manufacturing, blending performance, efficiency, and interpretability. Our method surpasses conventional approaches, offering precise nanomaterial identification and facilitating high-throughput screening.
Foundational Model for Electron Micrograph Analysis: Instruction-Tuning Small-Scale Language-and-Vision Assistant for Enterprise Adoption
Aug 23, 2024



Semiconductor imaging and analysis are critical yet understudied in deep learning, limiting our ability for precise control and optimization in semiconductor manufacturing. We introduce a small-scale multimodal framework for analyzing semiconductor electron microscopy images (MAEMI) through vision-language instruction tuning. We generate a customized instruction-following dataset using large multimodal models on microscopic image analysis. We perform knowledge transfer from larger to smaller models through knowledge distillation, resulting in improved accuracy of smaller models on visual question answering (VQA) tasks. This approach eliminates the need for expensive, human expert-annotated datasets for microscopic image analysis tasks. Enterprises can further finetune MAEMI on their intellectual data, enhancing privacy and performance on low-cost consumer hardware. Our experiments show that MAEMI outperforms traditional methods, adapts to data distribution shifts, and supports high-throughput screening.