 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhishMatch: A Layered Approach for Effective Detection of Phishing URLs
Paper and Code
Dec 04, 2021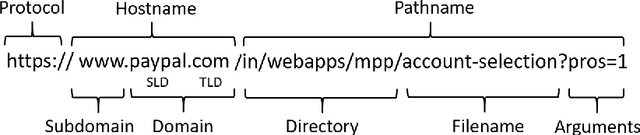

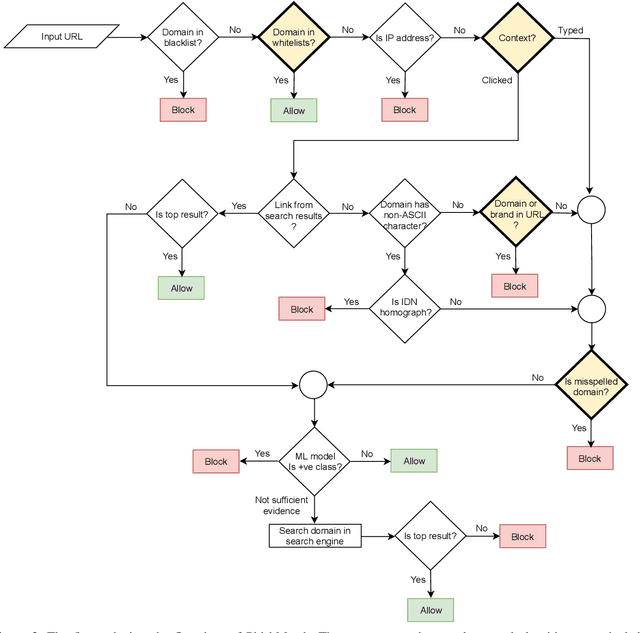
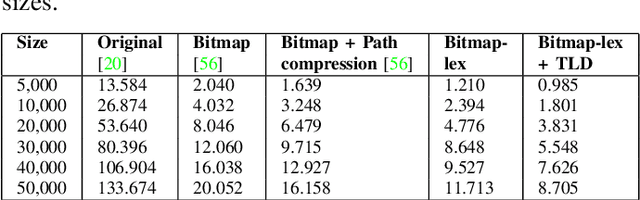
Phishing attacks continue to be a significant threat on the Internet. Prior studies show that it is possible to determine whether a website is phishing or not just by analyzing its URL more carefully. A major advantage of the URL based approach is that it can identify a phishing website even before the web page is rendered in the browser, thus avoiding other potential problems such as cryptojacking and drive-by downloads. However, traditional URL based approaches have their limitations. Blacklist based approaches are prone to zero-hour phishing attacks, advanced machine learning based approaches consume high resources, and other approaches send the URL to a remote server which compromises user's privacy. In this paper, we present a layered anti-phishing defense, PhishMatch, which is robust, accurate, inexpensive, and client-side. We design a space-time efficient Aho-Corasick algorithm for exact string matching and n-gram based indexing technique for approximate string matching to detect various cybersquatting techniques in the phishing URL. To reduce false positives, we use a global whitelist and personalized user whitelists. We also determine the context in which the URL is visited and use that information to classify the input URL more accurately. The last component of PhishMatch involves a machine learning model and controlled search engine queries to classify the URL. A prototype plugin of PhishMatch, developed for the Chrome browser, was found to be fast and lightweight. Our evaluation shows that PhishMatch is both efficient and effective.