 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluence Based Defense Against Data Poisoning Attacks in Online Learning
Paper and Code
Apr 24, 2021
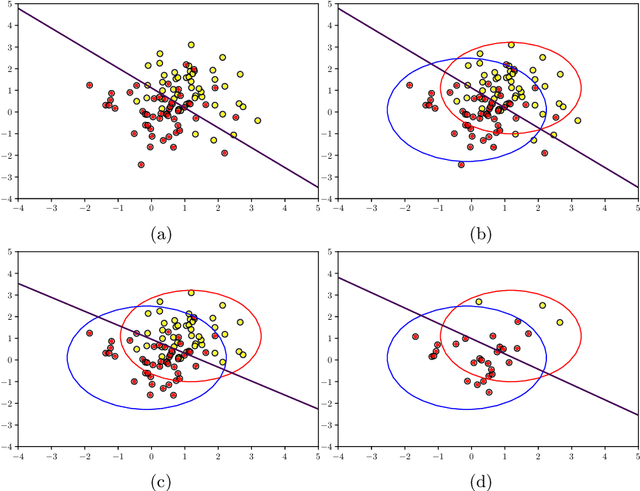
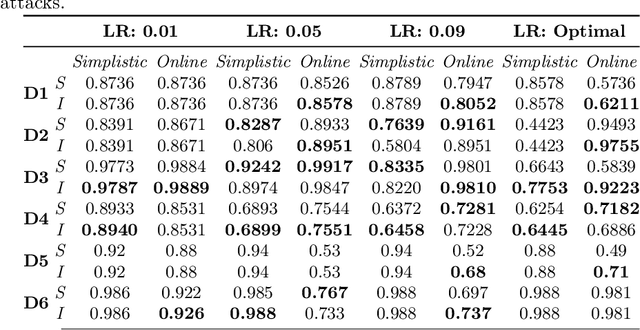
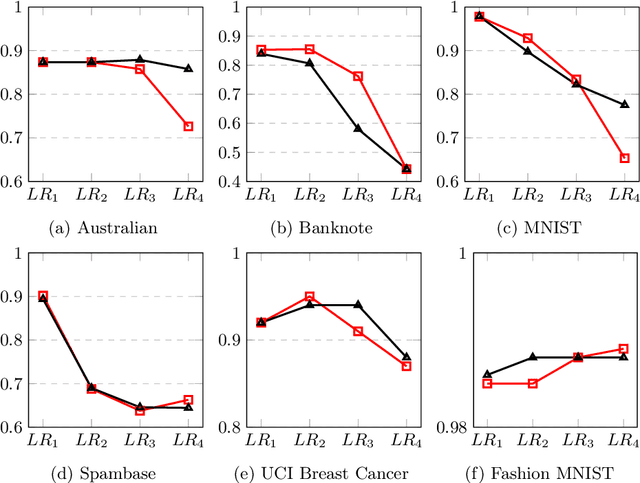
Data poisoning is a type of adversarial attack on training data where an attacker manipulates a fraction of data to degrade the performance of machine learning model. Therefore, applications that rely on external data-sources for training data are at a significantly higher risk. There are several known defensive mechanisms that can help in mitigating the threat from such attacks. For example, data sanitization is a popular defensive mechanism wherein the learner rejects those data points that are sufficiently far from the set of training instances. Prior work on data poisoning defense primarily focused on offline setting, wherein all the data is assumed to be available for analysis. Defensive measures for online learning, where data points arrive sequentially, have not garnered similar interest. In this work, we propose a defense mechanism to minimize the degradation caused by the poisoned training data on a learner's model in an online setup. Our proposed method utilizes an influence function which is a classic technique in robust statistics. Further, we supplement it with the existing data sanitization methods for filtering out some of the poisoned data points. We study the effectiveness of our defense mechanism on multiple datasets and across multiple attack strategies against an online learner.