 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based Data Subversion Attack Against Binary Classifiers
May 31, 2021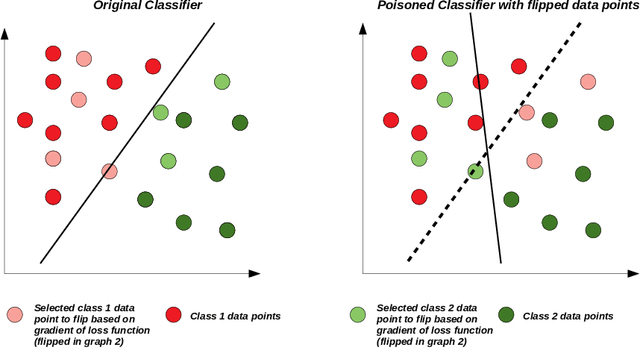
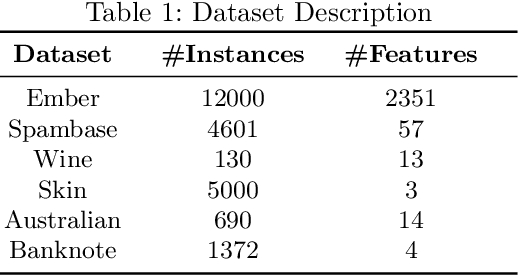
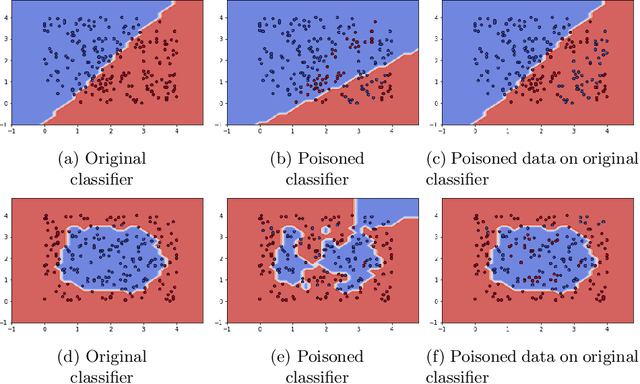
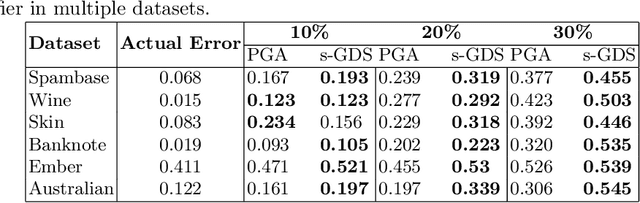
Machine learning based data-driven technologies have shown impressive performances in a variety of application domains. Most enterprises use data from multiple sources to provide quality applications. The reliability of the external data sources raises concerns for the security of the machine learning techniques adopted. An attacker can tamper the training or test datasets to subvert the predictions of models generated by these techniques. Data poisoning is one such attack wherein the attacker tries to degrade the performance of a classifier by manipulating the training data. In this work, we focus on label contamination attack in which an attacker poisons the labels of data to compromise the functionality of the system. We develop Gradient-based Data Subversion strategies to achieve model degradation under the assumption that the attacker has limited-knowledge of the victim model. We exploit the gradients of a differentiable convex loss function (residual errors) with respect to the predicted label as a warm-start and formulate different strategies to find a set of data instances to contaminate. Further, we analyze the transferability of attacks and the susceptibility of binary classifiers. Our experiments show that the proposed approach outperforms the baselines and is computationally efficient.
Influence Based Defense Against Data Poisoning Attacks in Online Learning
Apr 24, 2021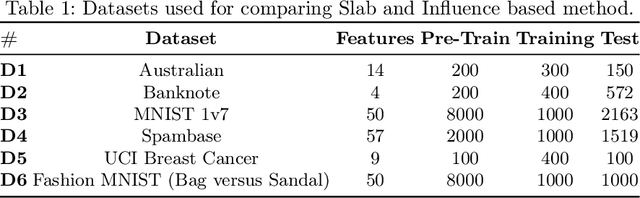
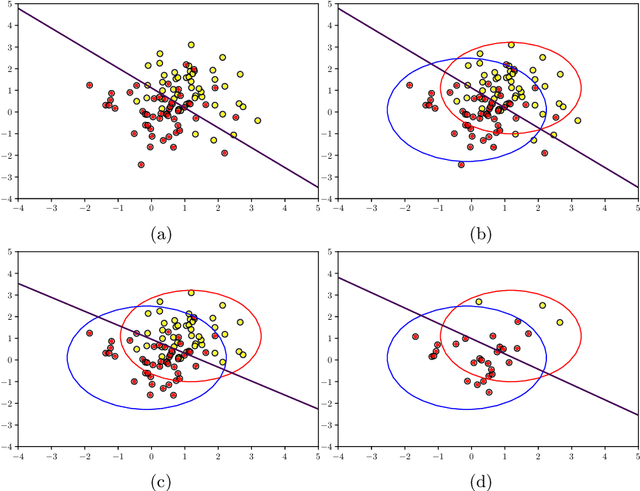
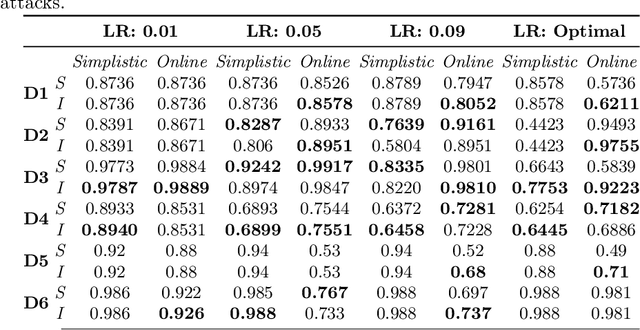
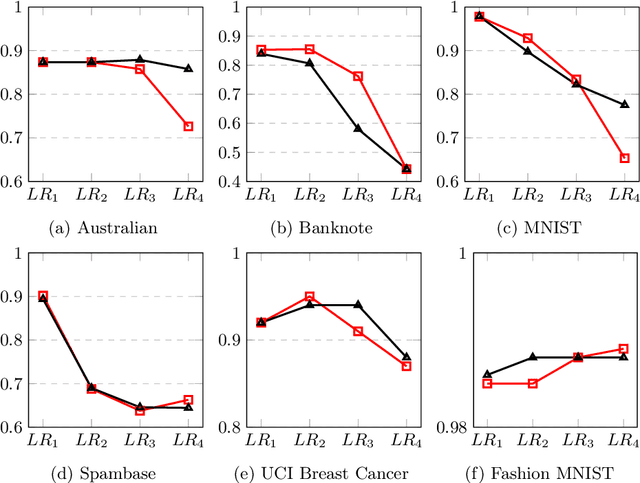
Data poisoning is a type of adversarial attack on training data where an attacker manipulates a fraction of data to degrade the performance of machine learning model. Therefore, applications that rely on external data-sources for training data are at a significantly higher risk. There are several known defensive mechanisms that can help in mitigating the threat from such attacks. For example, data sanitization is a popular defensive mechanism wherein the learner rejects those data points that are sufficiently far from the set of training instances. Prior work on data poisoning defense primarily focused on offline setting, wherein all the data is assumed to be available for analysis. Defensive measures for online learning, where data points arrive sequentially, have not garnered similar interest. In this work, we propose a defense mechanism to minimize the degradation caused by the poisoned training data on a learner's model in an online setup. Our proposed method utilizes an influence function which is a classic technique in robust statistics. Further, we supplement it with the existing data sanitization methods for filtering out some of the poisoned data points. We study the effectiveness of our defense mechanism on multiple datasets and across multiple attack strategies against an online learner.