 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust 3D Object Detection using Probabilistic Point Clouds from Single-Photon LiDARs
Jul 31, 2025LiDAR-based 3D sensors provide point clouds, a canonical 3D representation used in various scene understanding tasks. Modern LiDARs face key challenges in several real-world scenarios, such as long-distance or low-albedo objects, producing sparse or erroneous point clouds. These errors, which are rooted in the noisy raw LiDAR measurements, get propagated to downstream perception models, resulting in potentially severe loss of accuracy. This is because conventional 3D processing pipelines do not retain any uncertainty information from the raw measurements when constructing point clouds. We propose Probabilistic Point Clouds (PPC), a novel 3D scene representation where each point is augmented with a probability attribute that encapsulates the measurement uncertainty (or confidence) in the raw data. We further introduce inference approaches that leverage PPC for robust 3D object detection; these methods are versatile and can be used as computationally lightweight drop-in modules in 3D inference pipelines. We demonstrate, via both simulations and real captures, that PPC-based 3D inference methods outperform several baselines using LiDAR as well as camera-LiDAR fusion models, across challenging indoor and outdoor scenarios involving small, distant, and low-albedo objects, as well as strong ambient light. Our project webpage is at https://bhavyagoyal.github.io/ppc .
Robust Scene Inference under Noise-Blur Dual Corruptions
Jul 24, 2022
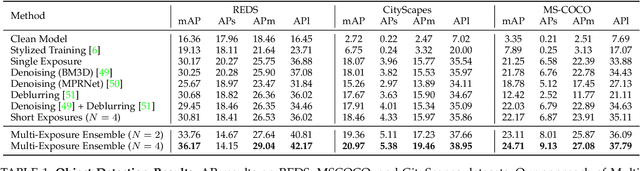


Scene inference under low-light is a challenging problem due to severe noise in the captured images. One way to reduce noise is to use longer exposure during the capture. However, in the presence of motion (scene or camera motion), longer exposures lead to motion blur, resulting in loss of image information. This creates a trade-off between these two kinds of image degradations: motion blur (due to long exposure) vs. noise (due to short exposure), also referred as a dual image corruption pair in this paper. With the rise of cameras capable of capturing multiple exposures of the same scene simultaneously, it is possible to overcome this trade-off. Our key observation is that although the amount and nature of degradation varies for these different image captures, the semantic content remains the same across all images. To this end, we propose a method to leverage these multi exposure captures for robust inference under low-light and motion. Our method builds on a feature consistency loss to encourage similar results from these individual captures, and uses the ensemble of their final predictions for robust visual recognition. We demonstrate the effectiveness of our approach on simulated images as well as real captures with multiple exposures, and across the tasks of object detection and image classification.
Photon-Starved Scene Inference using Single Photon Cameras
Aug 16, 2021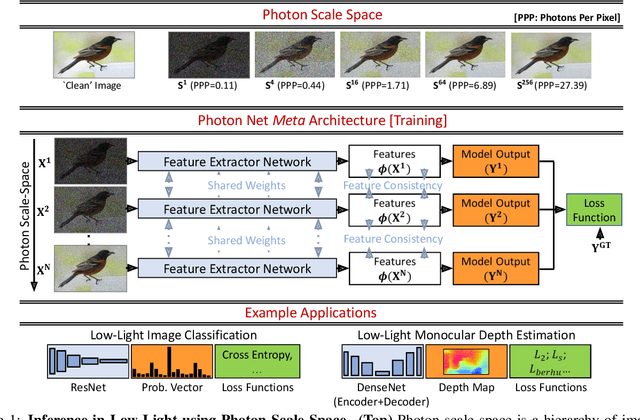



Scene understanding under low-light conditions is a challenging problem. This is due to the small number of photons captured by the camera and the resulting low signal-to-noise ratio (SNR). Single-photon cameras (SPCs) are an emerging sensing modality that are capable of capturing images with high sensitivity. Despite having minimal read-noise, images captured by SPCs in photon-starved conditions still suffer from strong shot noise, preventing reliable scene inference. We propose photon scale-space a collection of high-SNR images spanning a wide range of photons-per-pixel (PPP) levels (but same scene content) as guides to train inference model on low photon flux images. We develop training techniques that push images with different illumination levels closer to each other in feature representation space. The key idea is that having a spectrum of different brightness levels during training enables effective guidance, and increases robustness to shot noise even in extreme noise cases. Based on the proposed approach, we demonstrate, via simulations and real experiments with a SPAD camera, high-performance on various inference tasks such as image classification and monocular depth estimation under ultra low-light, down to < 1 PPP.
Attention-based Ensemble for Deep Metric Learning
Aug 31, 2018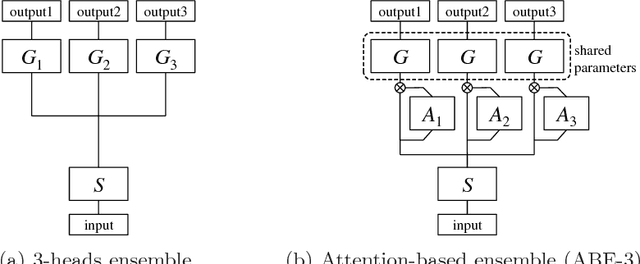
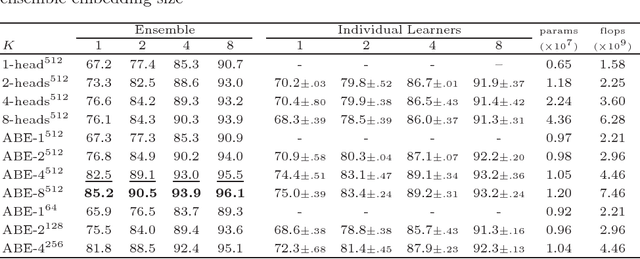
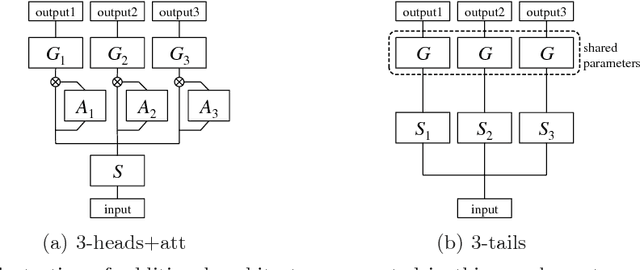

Deep metric learning aims to learn an embedding function, modeled as deep neural network. This embedding function usually puts semantically similar images close while dissimilar images far from each other in the learned embedding space. Recently, ensemble has been applied to deep metric learning to yield state-of-the-art results. As one important aspect of ensemble, the learners should be diverse in their feature embeddings. To this end, we propose an attention-based ensemble, which uses multiple attention masks, so that each learner can attend to different parts of the object. We also propose a divergence loss, which encourages diversity among the learners. The proposed method is applied to the standard benchmarks of deep metric learning and experimental results show that it outperforms the state-of-the-art methods by a significant margin on image retrieval tasks.