 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Representation Learning for Multimodal Tabular Transactions
Paper and Code
Oct 10, 2024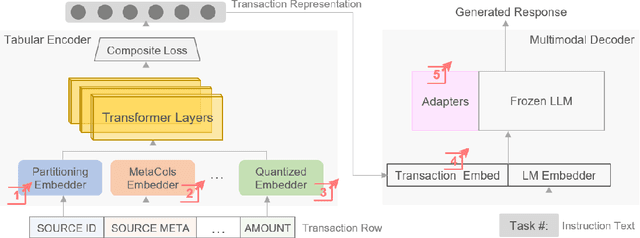
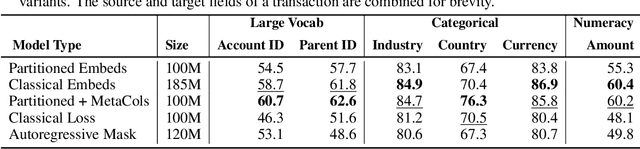
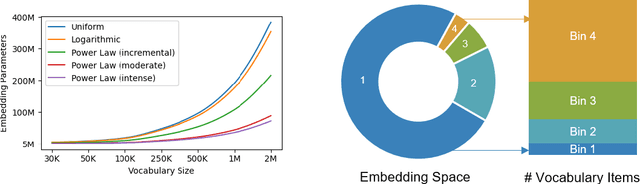
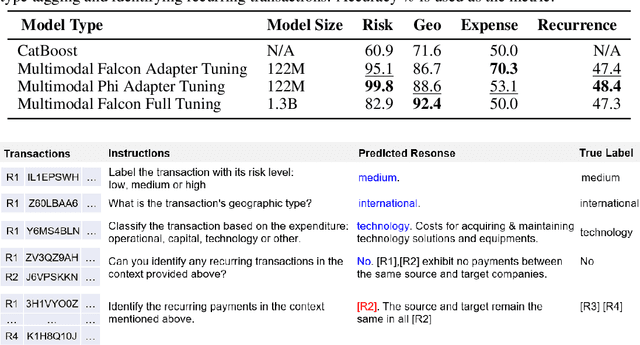
Large language models (LLMs) are primarily designed to understand unstructured text. When directly applied to structured formats such as tabular data, they may struggle to discern inherent relationships and overlook critical patterns. While tabular representation learning methods can address some of these limitations, existing efforts still face challenges with sparse high-cardinality fields, precise numerical reasoning, and column-heavy tables. Furthermore, leveraging these learned representations for downstream tasks through a language based interface is not apparent. In this paper, we present an innovative and scalable solution to these challenges. Concretely, our approach introduces a multi-tier partitioning mechanism that utilizes power-law dynamics to handle large vocabularies, an adaptive quantization mechanism to impose priors on numerical continuity, and a distinct treatment of core-columns and meta-information columns. To facilitate instruction tuning on LLMs, we propose a parameter efficient decoder that interleaves transaction and text modalities using a series of adapter layers, thereby exploiting rich cross-task knowledge. We validate the efficacy of our solution on a large-scale dataset of synthetic payments transactions.