 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Policy Gradients
Paper and Code
Feb 20, 2021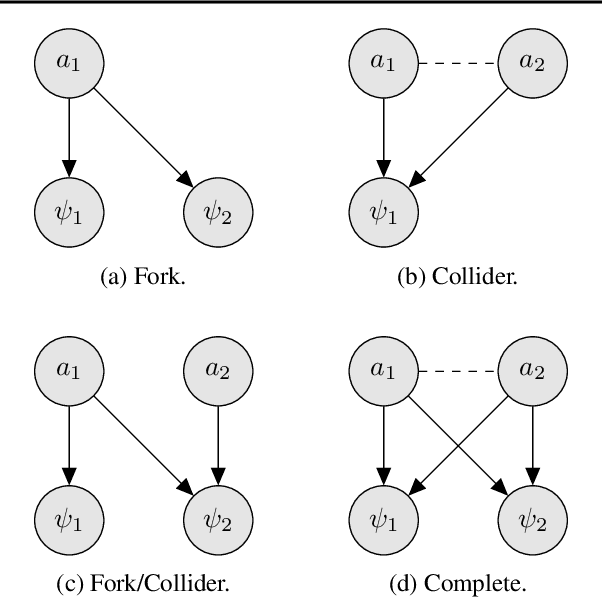
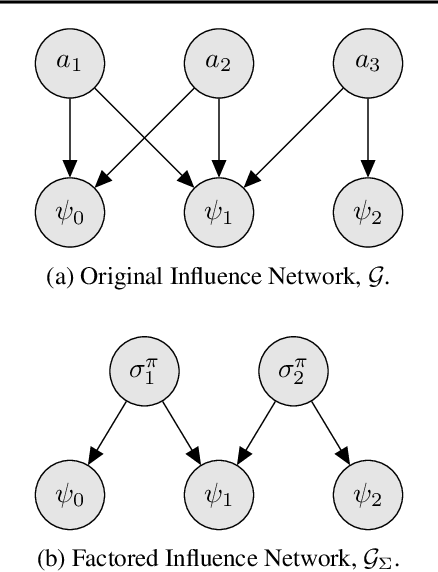
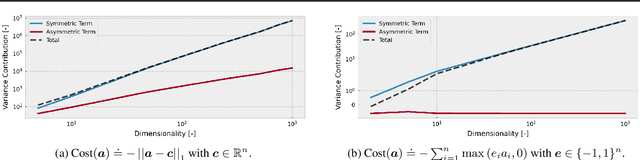
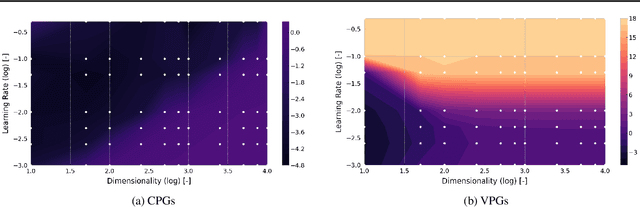
Policy gradient methods can solve complex tasks but often fail when the dimensionality of the action-space or objective multiplicity grow very large. This occurs, in part, because the variance on score-based gradient estimators scales quadratically with the number of targets. In this paper, we propose a causal baseline which exploits independence structure encoded in a novel action-target influence network. Causal policy gradients (CPGs), which follow, provide a common framework for analysing key state-of-the-art algorithms, are shown to generalise traditional policy gradients, and yield a principled way of incorporating prior knowledge of a problem domain's generative processes. We provide an analysis of the proposed estimator and identify the conditions under which variance is guaranteed to improve. The algorithmic aspects of CPGs are also discussed, including optimal policy factorisations, their complexity, and the use of conditioning to efficiently scale to extremely large, concurrent tasks. The performance advantages for two variants of the algorithm are demonstrated on large-scale bandit and concurrent inventory management problems.