 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForget to Generalize: Iterative Adaptation for Generalization in Federated Learning
Feb 04, 2026The Web is naturally heterogeneous with user devices, geographic regions, browsing patterns, and contexts all leading to highly diverse, unique datasets. Federated Learning (FL) is an important paradigm for the Web because it enables privacy-preserving, collaborative machine learning across diverse user devices, web services and clients without needing to centralize sensitive data. However, its performance degrades severely under non-IID client distributions that is prevalent in real-world web systems. In this work, we propose a new training paradigm - Iterative Federated Adaptation (IFA) - that enhances generalization in heterogeneous federated settings through generation-wise forget and evolve strategy. Specifically, we divide training into multiple generations and, at the end of each, select a fraction of model parameters (a) randomly or (b) from the later layers of the model and reinitialize them. This iterative forget and evolve schedule allows the model to escape local minima and preserve globally relevant representations. Extensive experiments on CIFAR-10, MIT-Indoors, and Stanford Dogs datasets show that the proposed approach improves global accuracy, especially when the data cross clients are Non-IID. This method can be implemented on top any federated algorithm to improve its generalization performance. We observe an average of 21.5%improvement across datasets. This work advances the vision of scalable, privacy-preserving intelligence for real-world heterogeneous and distributed web systems.
Knowledge Distillation for Federated Learning: a Practical Guide
Nov 09, 2022Federated Learning (FL) enables the training of Deep Learning models without centrally collecting possibly sensitive raw data. This paves the way for stronger privacy guarantees when building predictive models. The most used algorithms for FL are parameter-averaging based schemes (e.g., Federated Averaging) that, however, have well known limits: (i) Clients must implement the same model architecture; (ii) Transmitting model weights and model updates implies high communication cost, which scales up with the number of model parameters; (iii) In presence of non-IID data distributions, parameter-averaging aggregation schemes perform poorly due to client model drifts. Federated adaptations of regular Knowledge Distillation (KD) can solve and/or mitigate the weaknesses of parameter-averaging FL algorithms while possibly introducing other trade-offs. In this article, we provide a review of KD-based algorithms tailored for specific FL issues.
Gradient Masked Averaging for Federated Learning
Jan 28, 2022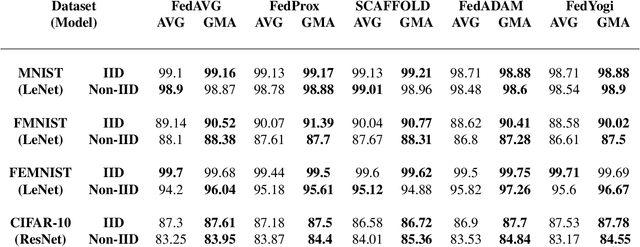
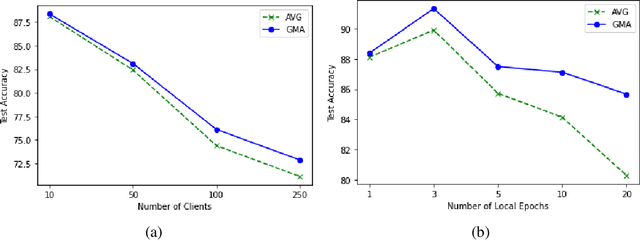

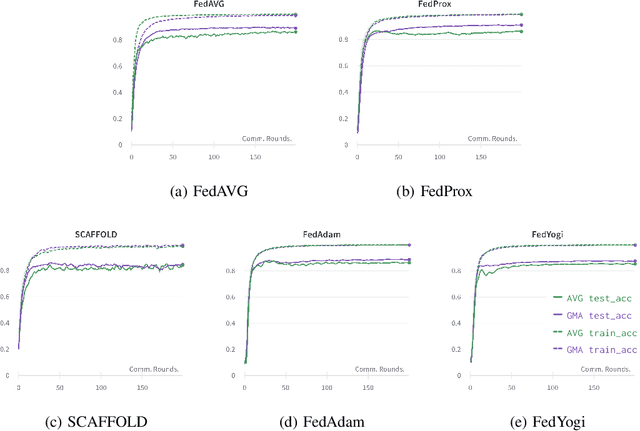
Federated learning is an emerging paradigm that permits a large number of clients with heterogeneous data to coordinate learning of a unified global model without the need to share data amongst each other. Standard federated learning algorithms involve averaging of model parameters or gradient updates to approximate the global model at the server. However, in heterogeneous settings averaging can result in information loss and lead to poor generalization due to the bias induced by dominant clients. We hypothesize that to generalize better across non-i.i.d datasets as in FL settings, the algorithms should focus on learning the invariant mechanism that is constant while ignoring spurious mechanisms that differ across clients. Inspired from recent work in the Out-of-Distribution literature, we propose a gradient masked averaging approach for federated learning as an alternative to the standard averaging of client updates. This client update aggregation technique can be adapted as a drop-in replacement in most existing federated algorithms. We perform extensive experiments with gradient masked approach on multiple FL algorithms with in-distribution, real-world, and out-of-distribution (as the worst case scenario) test dataset and show that it provides consistent improvements, particularly in the case of heterogeneous clients.
Gradient Masked Federated Optimization
Apr 21, 2021
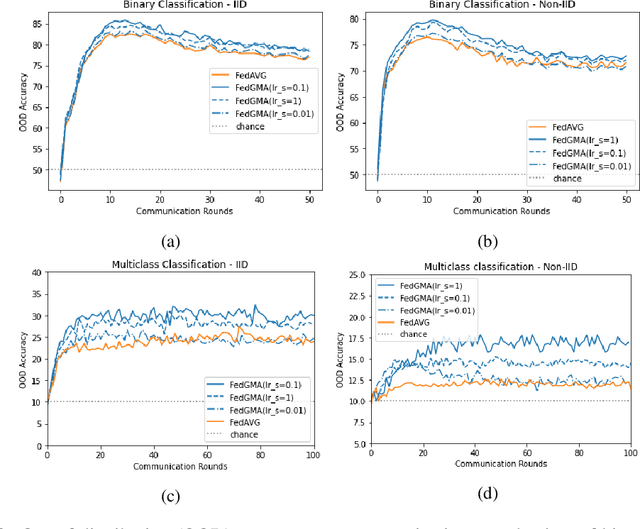


Federated Averaging (FedAVG) has become the most popular federated learning algorithm due to its simplicity and low communication overhead. We use simple examples to show that FedAVG has the tendency to sew together the optima across the participating clients. These sewed optima exhibit poor generalization when used on a new client with new data distribution. Inspired by the invariance principles in (Arjovsky et al., 2019; Parascandolo et al., 2020), we focus on learning a model that is locally optimal across the different clients simultaneously. We propose a modification to FedAVG algorithm to include masked gradients (AND-mask from (Parascandolo et al., 2020)) across the clients and uses them to carry out an additional server model update. We show that this algorithm achieves better accuracy (out-of-distribution) than FedAVG, especially when the data is non-identically distributed across clients.
Towards Causal Federated Learning For Enhanced Robustness and Privacy
Apr 14, 2021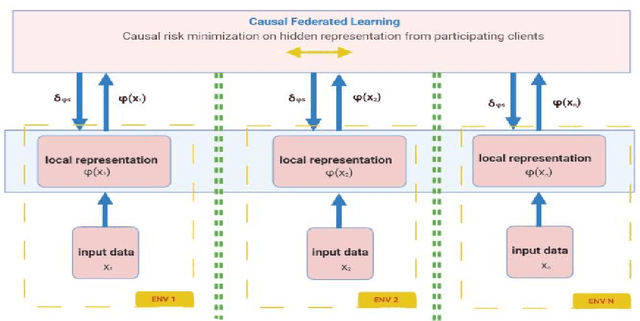
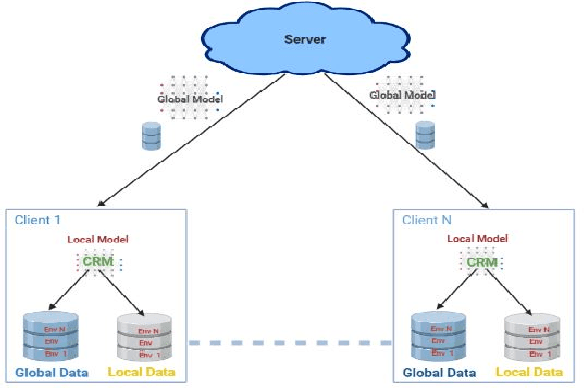

Federated Learning is an emerging privacy-preserving distributed machine learning approach to building a shared model by performing distributed training locally on participating devices (clients) and aggregating the local models into a global one. As this approach prevents data collection and aggregation, it helps in reducing associated privacy risks to a great extent. However, the data samples across all participating clients are usually not independent and identically distributed (non-iid), and Out of Distribution(OOD) generalization for the learned models can be poor. Besides this challenge, federated learning also remains vulnerable to various attacks on security wherein a few malicious participating entities work towards inserting backdoors, degrading the generated aggregated model as well as inferring the data owned by participating entities. In this paper, we propose an approach for learning invariant (causal) features common to all participating clients in a federated learning setup and analyze empirically how it enhances the Out of Distribution (OOD) accuracy as well as the privacy of the final learned model.