 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk Aversion In Learning Algorithms and an Application To Recommendation Systems
Paper and Code
May 10, 2022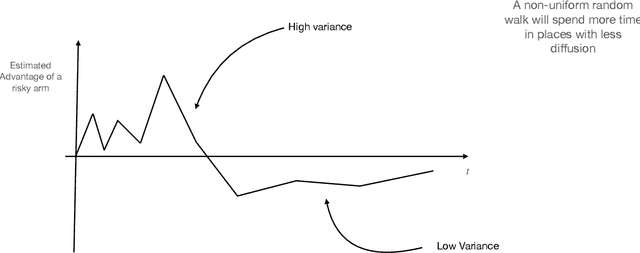
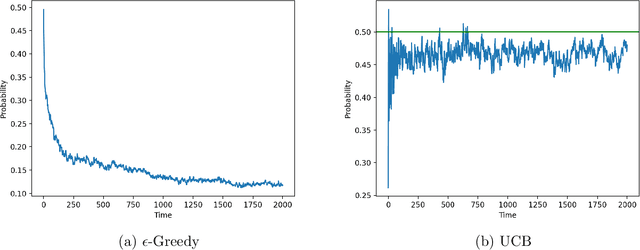
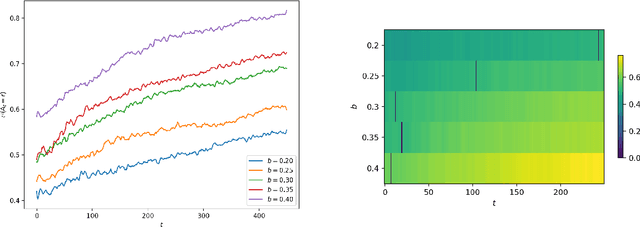
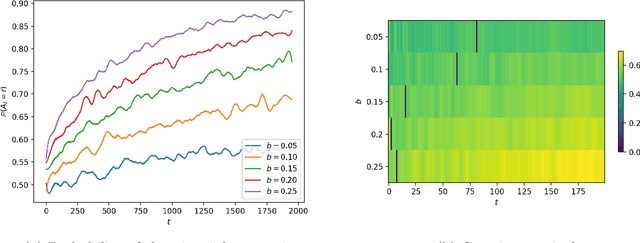
Consider a bandit learning environment. We demonstrate that popular learning algorithms such as Upper Confidence Band (UCB) and $\varepsilon$-Greedy exhibit risk aversion: when presented with two arms of the same expectation, but different variance, the algorithms tend to not choose the riskier, i.e. higher variance, arm. We prove that $\varepsilon$-Greedy chooses the risky arm with probability tending to $0$ when faced with a deterministic and a Rademacher-distributed arm. We show experimentally that UCB also shows risk-averse behavior, and that risk aversion is present persistently in early rounds of learning even if the riskier arm has a slightly higher expectation. We calibrate our model to a recommendation system and show that algorithmic risk aversion can decrease consumer surplus and increase homogeneity. We discuss several extensions to other bandit algorithms, reinforcement learning, and investigate the impacts of algorithmic risk aversion for decision theory.