 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explainable Natural Language Framework for Identifying and Notifying Target Audiences In Enterprise Communication
Aug 07, 2025In large-scale maintenance organizations, identifying subject matter experts and managing communications across complex entities relationships poses significant challenges -- including information overload and longer response times -- that traditional communication approaches fail to address effectively. We propose a novel framework that combines RDF graph databases with LLMs to process natural language queries for precise audience targeting, while providing transparent reasoning through a planning-orchestration architecture. Our solution enables communication owners to formulate intuitive queries combining concepts such as equipment, manufacturers, maintenance engineers, and facilities, delivering explainable results that maintain trust in the system while improving communication efficiency across the organization.
Modeling and Optimizing Laser-Induced Graphene
Jul 29, 2021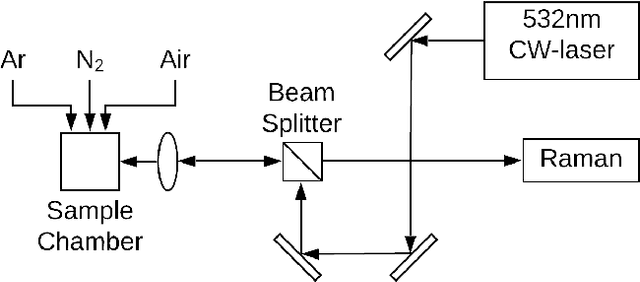
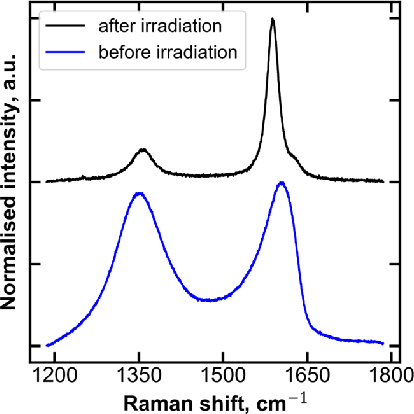
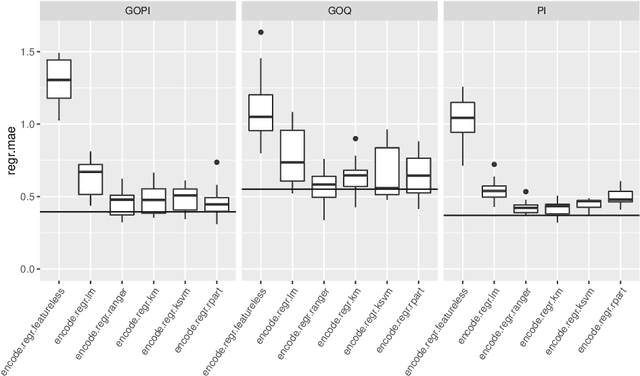
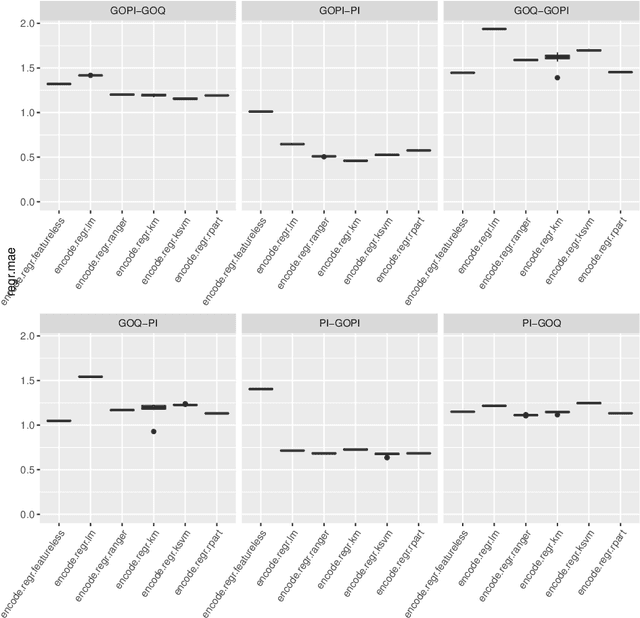
A lot of technological advances depend on next-generation materials, such as graphene, which enables a raft of new applications, for example better electronics. Manufacturing such materials is often difficult; in particular, producing graphene at scale is an open problem. We provide a series of datasets that describe the optimization of the production of laser-induced graphene, an established manufacturing method that has shown great promise. We pose three challenges based on the datasets we provide -- modeling the behavior of laser-induced graphene production with respect to parameters of the production process, transferring models and knowledge between different precursor materials, and optimizing the outcome of the transformation over the space of possible production parameters. We present illustrative results, along with the code used to generate them, as a starting point for interested users. The data we provide represents an important real-world application of machine learning; to the best of our knowledge, no similar datasets are available.
DeepTriage: Automated Transfer Assistance for Incidents in Cloud Services
Nov 25, 2020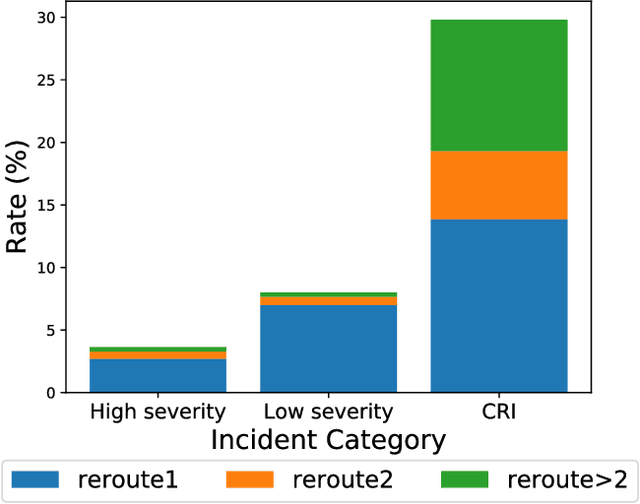
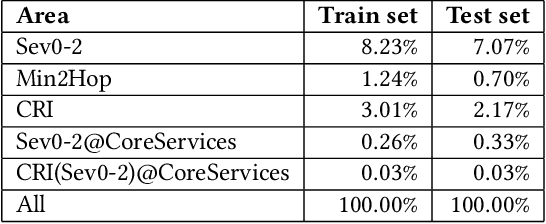
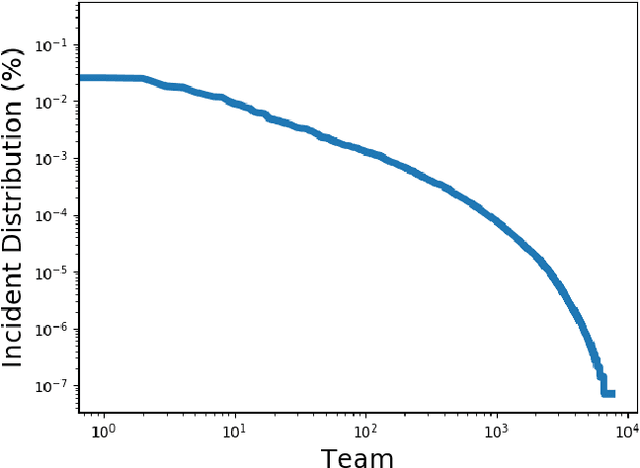
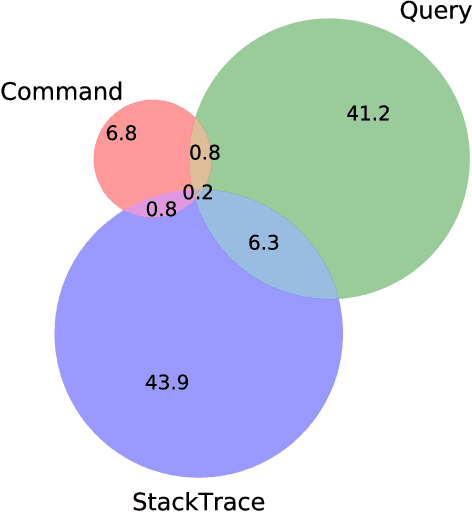
As cloud services are growing and generating high revenues, the cost of downtime in these services is becoming significantly expensive. To reduce loss and service downtime, a critical primary step is to execute incident triage, the process of assigning a service incident to the correct responsible team, in a timely manner. An incorrect assignment risks additional incident reroutings and increases its time to mitigate by 10x. However, automated incident triage in large cloud services faces many challenges: (1) a highly imbalanced incident distribution from a large number of teams, (2) wide variety in formats of input data or data sources, (3) scaling to meet production-grade requirements, and (4) gaining engineers' trust in using machine learning recommendations. To address these challenges, we introduce DeepTriage, an intelligent incident transfer service combining multiple machine learning techniques - gradient boosted classifiers, clustering methods, and deep neural networks - in an ensemble to recommend the responsible team to triage an incident. Experimental results on real incidents in Microsoft Azure show that our service achieves 82.9% F1 score. For highly impacted incidents, DeepTriage achieves F1 score from 76.3% - 91.3%. We have applied best practices and state-of-the-art frameworks to scale DeepTriage to handle incident routing for all cloud services. DeepTriage has been deployed in Azure since October 2017 and is used by thousands of teams daily.