 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepTriage: Automated Transfer Assistance for Incidents in Cloud Services
Nov 25, 2020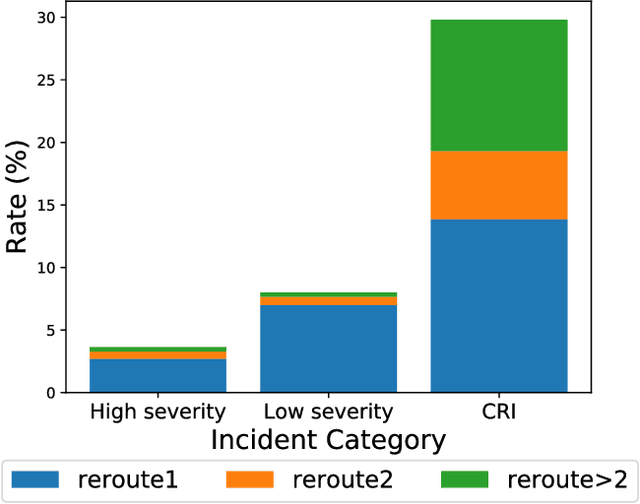
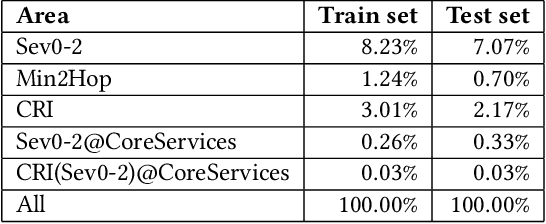
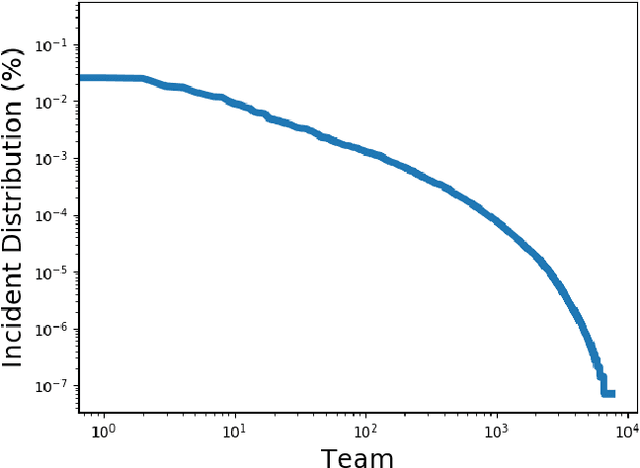
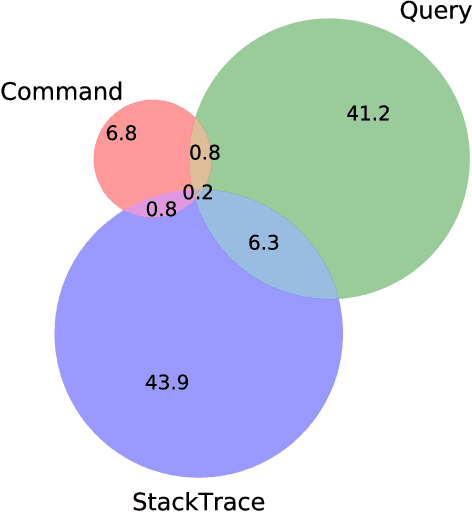
As cloud services are growing and generating high revenues, the cost of downtime in these services is becoming significantly expensive. To reduce loss and service downtime, a critical primary step is to execute incident triage, the process of assigning a service incident to the correct responsible team, in a timely manner. An incorrect assignment risks additional incident reroutings and increases its time to mitigate by 10x. However, automated incident triage in large cloud services faces many challenges: (1) a highly imbalanced incident distribution from a large number of teams, (2) wide variety in formats of input data or data sources, (3) scaling to meet production-grade requirements, and (4) gaining engineers' trust in using machine learning recommendations. To address these challenges, we introduce DeepTriage, an intelligent incident transfer service combining multiple machine learning techniques - gradient boosted classifiers, clustering methods, and deep neural networks - in an ensemble to recommend the responsible team to triage an incident. Experimental results on real incidents in Microsoft Azure show that our service achieves 82.9% F1 score. For highly impacted incidents, DeepTriage achieves F1 score from 76.3% - 91.3%. We have applied best practices and state-of-the-art frameworks to scale DeepTriage to handle incident routing for all cloud services. DeepTriage has been deployed in Azure since October 2017 and is used by thousands of teams daily.