 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnicorn: Reasoning about Configurable System Performance through the lens of Causality
Jan 20, 2022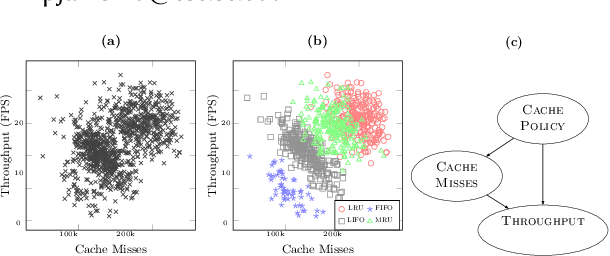
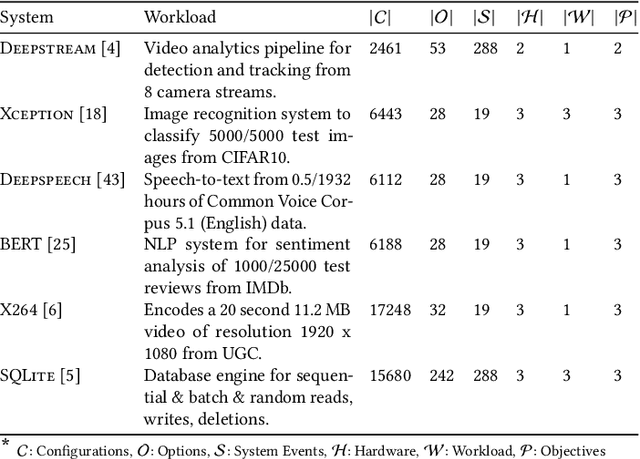
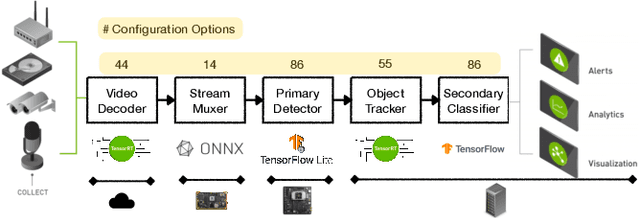
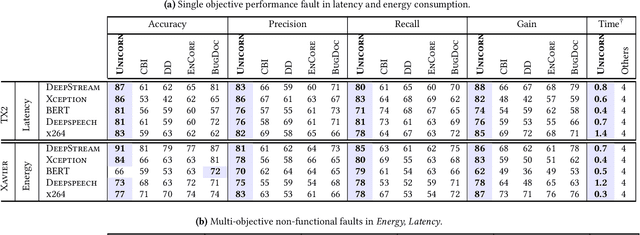
Modern computer systems are highly configurable, with the variability space sometimes larger than the number of atoms in the universe. Understanding and reasoning about the performance behavior of highly configurable systems, due to a vast variability space, is challenging. State-of-the-art methods for performance modeling and analyses rely on predictive machine learning models, therefore, they become (i) unreliable in unseen environments (e.g., different hardware, workloads), and (ii) produce incorrect explanations. To this end, we propose a new method, called Unicorn, which (a) captures intricate interactions between configuration options across the software-hardware stack and (b) describes how such interactions impact performance variations via causal inference. We evaluated Unicorn on six highly configurable systems, including three on-device machine learning systems, a video encoder, a database management system, and a data analytics pipeline. The experimental results indicate that Unicorn outperforms state-of-the-art performance optimization and debugging methods. Furthermore, unlike the existing methods, the learned causal performance models reliably predict performance for new environments.
FlexiBO: Cost-Aware Multi-Objective Optimization of Deep Neural Networks
Jan 18, 2020
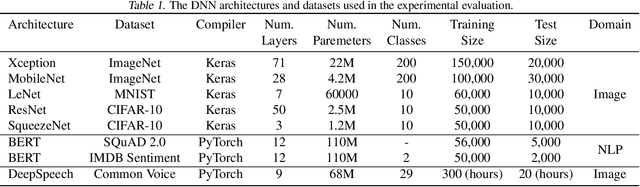
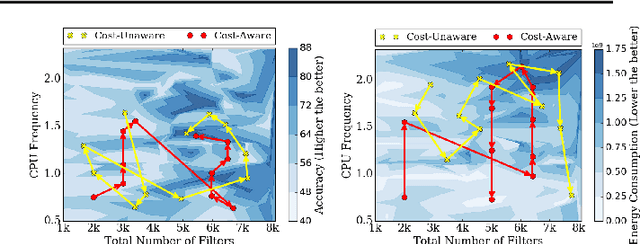
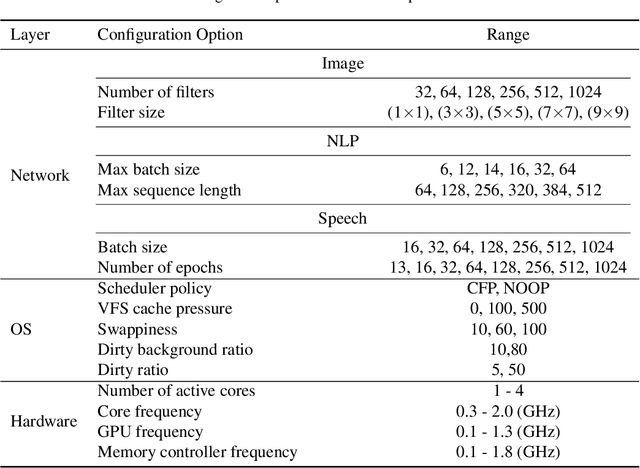
One of the key challenges in designing machine learning systems is to determine the right balance amongst several objectives, which also oftentimes are incommensurable and conflicting. For example, when designing deep neural networks (DNNs), one often has to trade-off between multiple objectives, such as accuracy, energy consumption, and inference time. Typically, there is no single configuration that performs equally well for all objectives. Consequently, one is interested in identifying Pareto-optimal designs. Although different multi-objective optimization algorithms have been developed to identify Pareto-optimal configurations, state-of-the-art multi-objective optimization methods do not consider the different evaluation costs attending the objectives under consideration. This is particularly important for optimizing DNNs: the cost arising on account of assessing the accuracy of DNNs is orders of magnitude higher than that of measuring the energy consumption of pre-trained DNNs. We propose FlexiBO, a flexible Bayesian optimization method, to address this issue. We formulate a new acquisition function based on the improvement of the Pareto hyper-volume weighted by the measurement cost of each objective. Our acquisition function selects the next sample and objective that provides maximum information gain per unit of cost. We evaluated FlexiBO on 7 state-of-the-art DNNs for object detection, natural language processing, and speech recognition. Our results indicate that, when compared to other state-of-the-art methods across the 7 architectures we tested, the Pareto front obtained using FlexiBO has, on average, a 28.44% higher contribution to the true Pareto front and achieves 25.64% better diversity.
Transfer Learning for Performance Modeling of Deep Neural Network Systems
Apr 04, 2019
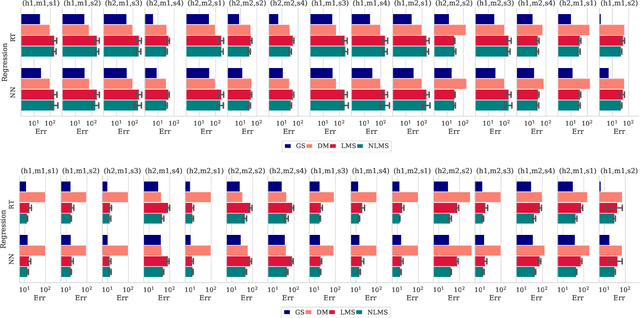
Modern deep neural network (DNN) systems are highly configurable with large a number of options that significantly affect their non-functional behavior, for example inference time and energy consumption. Performance models allow to understand and predict the effects of such configuration options on system behavior, but are costly to build because of large configuration spaces. Performance models from one environment cannot be transferred directly to another; usually models are rebuilt from scratch for different environments, for example different hardware. Recently, transfer learning methods have been applied to reuse knowledge from performance models trained in one environment in another. In this paper, we perform an empirical study to understand the effectiveness of different transfer learning strategies for building performance models of DNN systems. Our results show that transferring information on the most influential configuration options and their interactions is an effective way of reducing the cost to build performance models in new environments.