 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating machine learning models in non-standard settings: An overview and new findings
Paper and Code
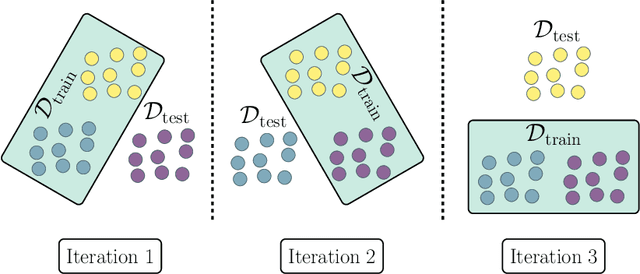

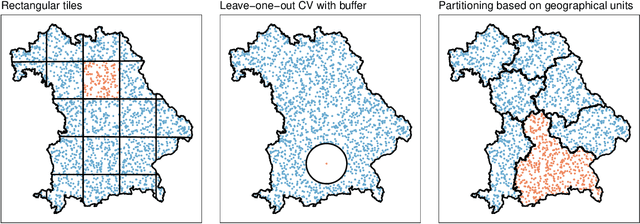

Estimating the generalization error (GE) of machine learning models is fundamental, with resampling methods being the most common approach. However, in non-standard settings, particularly those where observations are not independently and identically distributed, resampling using simple random data divisions may lead to biased GE estimates. This paper strives to present well-grounded guidelines for GE estimation in various such non-standard settings: clustered data, spatial data, unequal sampling probabilities, concept drift, and hierarchically structured outcomes. Our overview combines well-established methodologies with other existing methods that, to our knowledge, have not been frequently considered in these particular settings. A unifying principle among these techniques is that the test data used in each iteration of the resampling procedure should reflect the new observations to which the model will be applied, while the training data should be representative of the entire data set used to obtain the final model. Beyond providing an overview, we address literature gaps by conducting simulation studies. These studies assess the necessity of using GE-estimation methods tailored to the respective setting. Our findings corroborate the concern that standard resampling methods often yield biased GE estimates in non-standard settings, underscoring the importance of tailored GE estimation.