 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reducing Data Acquisition and Labeling for Defect Detection using Simulated Data
Jun 27, 2024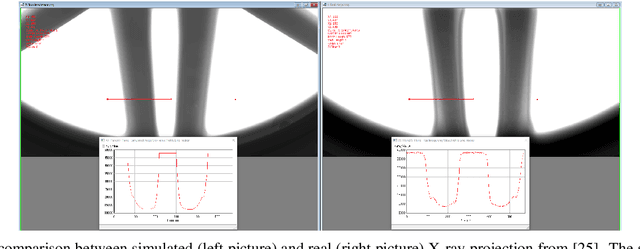
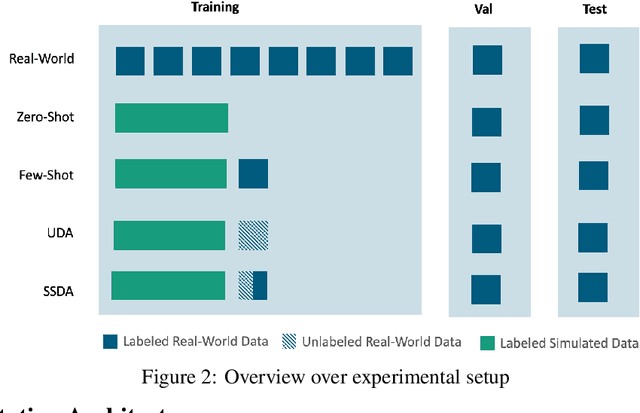
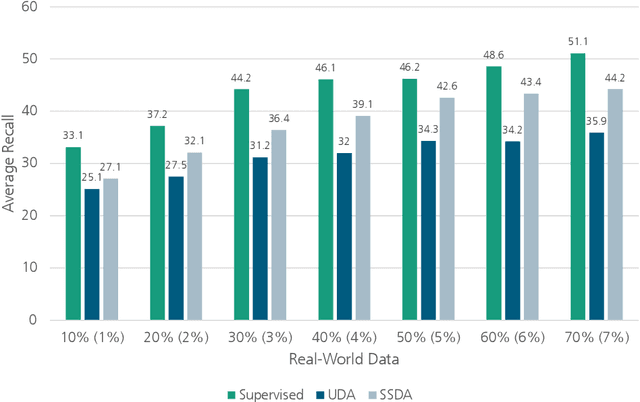
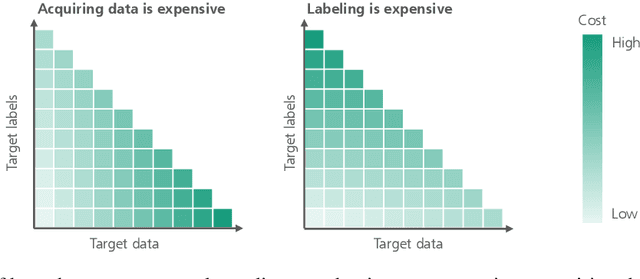
In many manufacturing settings, annotating data for machine learning and computer vision is costly, but synthetic data can be generated at significantly lower cost. Substituting the real-world data with synthetic data is therefore appealing for many machine learning applications that require large amounts of training data. However, relying solely on synthetic data is frequently inadequate for effectively training models that perform well on real-world data, primarily due to domain shifts between the synthetic and real-world data. We discuss approaches for dealing with such a domain shift when detecting defects in X-ray scans of aluminium wheels. Using both simulated and real-world X-ray images, we train an object detection model with different strategies to identify the training approach that generates the best detection results while minimising the demand for annotated real-world training samples. Our preliminary findings suggest that the sim-2-real domain adaptation approach is more cost-efficient than a fully supervised oracle - if the total number of available annotated samples is fixed. Given a certain number of labeled real-world samples, training on a mix of synthetic and unlabeled real-world data achieved comparable or even better detection results at significantly lower cost. We argue that future research into the cost-efficiency of different training strategies is important for a better understanding of how to allocate budget in applied machine learning projects.
Position: Embracing Negative Results in Machine Learning
Jun 06, 2024Publications proposing novel machine learning methods are often primarily rated by exhibited predictive performance on selected problems. In this position paper we argue that predictive performance alone is not a good indicator for the worth of a publication. Using it as such even fosters problems like inefficiencies of the machine learning research community as a whole and setting wrong incentives for researchers. We therefore put out a call for the publication of "negative" results, which can help alleviate some of these problems and improve the scientific output of the machine learning research community. To substantiate our position, we present the advantages of publishing negative results and provide concrete measures for the community to move towards a paradigm where their publication is normalized.