 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Analysis of the Impact of Data Augmentation on Knowledge Distillation
Jun 09, 2020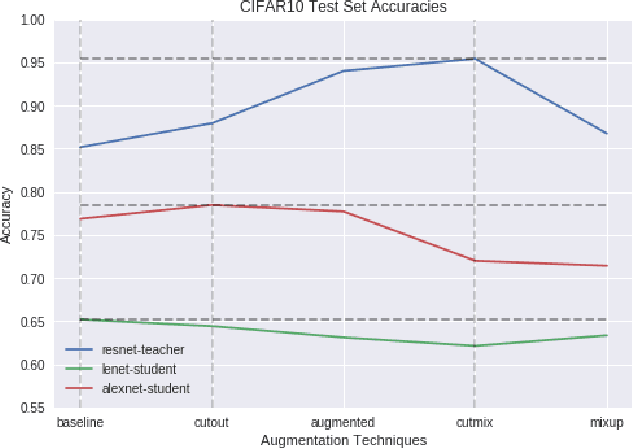
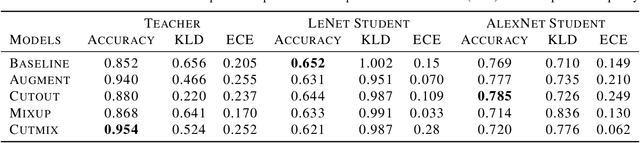


Generalization Performance of Deep Learning models trained using Empirical Risk Minimization can be improved significantly by using Data Augmentation strategies such as simple transformations, or using Mixed Samples. We attempt to empirically analyze the impact of such strategies on the transfer of generalization between teacher and student models in a distillation setup. We observe that if a teacher is trained using any of the mixed sample augmentation strategies, such as MixUp or CutMix, the student model distilled from it is impaired in its generalization capabilities. We hypothesize that such strategies limit a model's capability to learn example-specific features, leading to a loss in quality of the supervision signal during distillation. We present a novel Class-Discrimination metric to quantitatively measure this dichotomy in performance and link it to the discriminative capacity induced by the different strategies on a network's latent space.