 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi Supervised Phrase Localization in a Bidirectional Caption-Image Retrieval Framework
Aug 08, 2019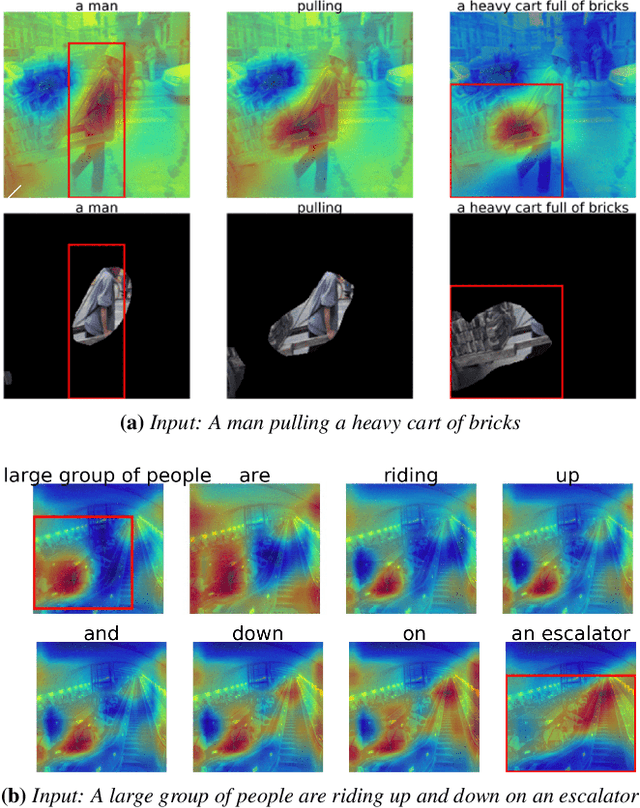
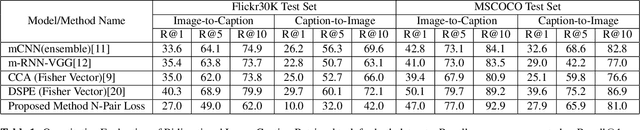
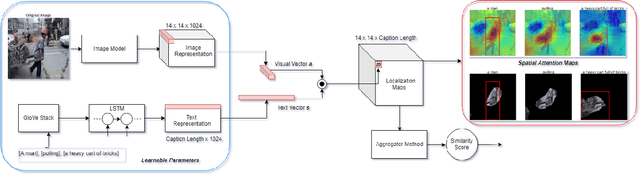
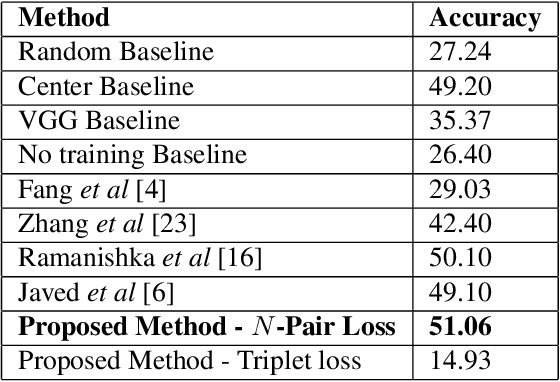
We introduce a novel deep neural network architecture that links visual regions to corresponding textual segments including phrases and words. To accomplish this task, our architecture makes use of the rich semantic information available in a joint embedding space of multi-modal data. From this joint embedding space, we extract the associative localization maps that develop naturally, without explicitly providing supervision during training for the localization task. The joint space is learned using a bidirectional ranking objective that is optimized using a $N$-Pair loss formulation. This training mechanism demonstrates the idea that localization information is learned inherently while optimizing a Bidirectional Retrieval objective. The model's retrieval and localization performance is evaluated on MSCOCO and Flickr30K Entities datasets. This architecture outperforms the state of the art results in the semi-supervised phrase localization setting.