 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho's Thinking? A Push for Human-Centered Evaluation of LLMs using the XAI Playbook
Mar 10, 2023Deployed artificial intelligence (AI) often impacts humans, and there is no one-size-fits-all metric to evaluate these tools. Human-centered evaluation of AI-based systems combines quantitative and qualitative analysis and human input. It has been explored to some depth in the explainable AI (XAI) and human-computer interaction (HCI) communities. Gaps remain, but the basic understanding that humans interact with AI and accompanying explanations, and that humans' needs -- complete with their cognitive biases and quirks -- should be held front and center, is accepted by the community. In this paper, we draw parallels between the relatively mature field of XAI and the rapidly evolving research boom around large language models (LLMs). Accepted evaluative metrics for LLMs are not human-centered. We argue that many of the same paths tread by the XAI community over the past decade will be retread when discussing LLMs. Specifically, we argue that humans' tendencies -- again, complete with their cognitive biases and quirks -- should rest front and center when evaluating deployed LLMs. We outline three developed focus areas of human-centered evaluation of XAI: mental models, use case utility, and cognitive engagement, and we highlight the importance of exploring each of these concepts for LLMs. Our goal is to jumpstart human-centered LLM evaluation.
Tensions Between the Proxies of Human Values in AI
Dec 14, 2022Motivated by mitigating potentially harmful impacts of technologies, the AI community has formulated and accepted mathematical definitions for certain pillars of accountability: e.g. privacy, fairness, and model transparency. Yet, we argue this is fundamentally misguided because these definitions are imperfect, siloed constructions of the human values they hope to proxy, while giving the guise that those values are sufficiently embedded in our technologies. Under popularized methods, tensions arise when practitioners attempt to achieve each pillar of fairness, privacy, and transparency in isolation or simultaneously. In this position paper, we push for redirection. We argue that the AI community needs to consider all the consequences of choosing certain formulations of these pillars -- not just the technical incompatibilities, but also the effects within the context of deployment. We point towards sociotechnical research for frameworks for the latter, but push for broader efforts into implementing these in practice.
Algorithmic Recourse in the Face of Noisy Human Responses
Mar 13, 2022

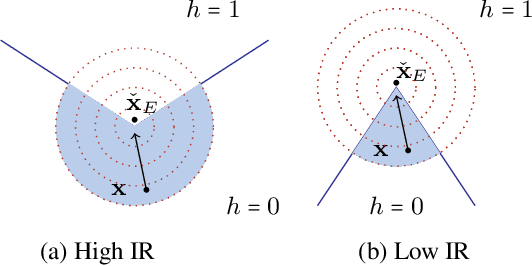

As machine learning (ML) models are increasingly being deployed in high-stakes applications, there has been growing interest in providing recourse to individuals adversely impacted by model predictions (e.g., an applicant whose loan has been denied). To this end, several post hoc techniques have been proposed in recent literature. These techniques generate recourses under the assumption that the affected individuals will implement the prescribed recourses exactly. However, recent studies suggest that individuals often implement recourses in a noisy and inconsistent manner - e.g., raising their salary by \$505 if the prescribed recourse suggested an increase of \$500. Motivated by this, we introduce and study the problem of recourse invalidation in the face of noisy human responses. More specifically, we theoretically and empirically analyze the behavior of state-of-the-art algorithms, and demonstrate that the recourses generated by these algorithms are very likely to be invalidated if small changes are made to them. We further propose a novel framework, EXPECTing noisy responses (EXPECT), which addresses the aforementioned problem by explicitly minimizing the probability of recourse invalidation in the face of noisy responses. Experimental evaluation with multiple real world datasets demonstrates the efficacy of the proposed framework, and supports our theoretical findings