Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Synthesis of Insurance Datasets
Paper and Code


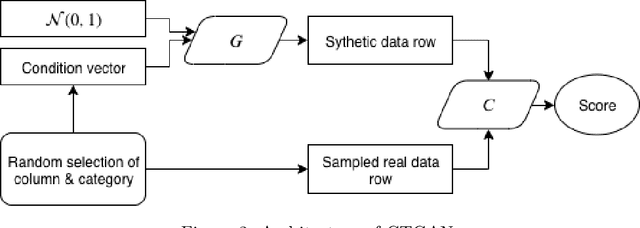

One of the impediments in advancing actuarial research and developing open source assets for insurance analytics is the lack of realistic publicly available datasets. In this work, we develop a workflow for synthesizing insurance datasets leveraging state-of-the-art neural network techniques. We evaluate the predictive modeling efficacy of datasets synthesized from publicly available data in the domains of general insurance pricing and life insurance shock lapse modeling. The trained synthesizers are able to capture representative characteristics of the real datasets. This workflow is implemented via an R interface to promote adoption by researchers and data owners.
View paper on