 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fair Federated Recommendation Learning: Characterizing the Inter-Dependence of System and Data Heterogeneity
Paper and Code
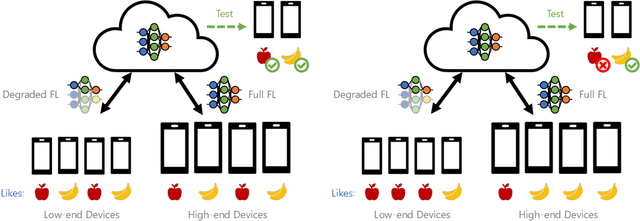
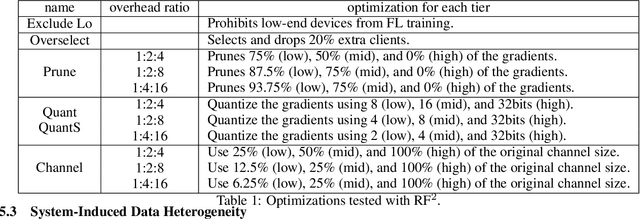
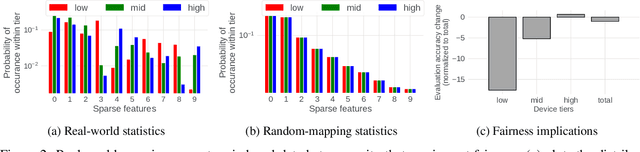
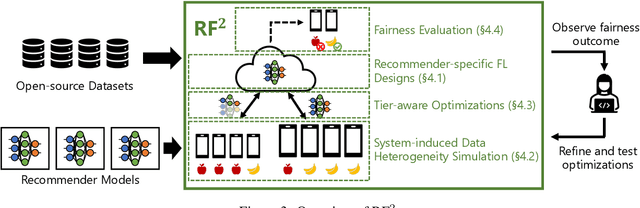
Federated learning (FL) is an effective mechanism for data privacy in recommender systems by running machine learning model training on-device. While prior FL optimizations tackled the data and system heterogeneity challenges faced by FL, they assume the two are independent of each other. This fundamental assumption is not reflective of real-world, large-scale recommender systems -- data and system heterogeneity are tightly intertwined. This paper takes a data-driven approach to show the inter-dependence of data and system heterogeneity in real-world data and quantifies its impact on the overall model quality and fairness. We design a framework, RF^2, to model the inter-dependence and evaluate its impact on state-of-the-art model optimization techniques for federated recommendation tasks. We demonstrate that the impact on fairness can be severe under realistic heterogeneity scenarios, by up to 15.8--41x compared to a simple setup assumed in most (if not all) prior work. It means when realistic system-induced data heterogeneity is not properly modeled, the fairness impact of an optimization can be downplayed by up to 41x. The result shows that modeling realistic system-induced data heterogeneity is essential to achieving fair federated recommendation learning. We plan to open-source RF^2 to enable future design and evaluation of FL innovations.