 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Deep Ensembles by Estimating Confusion Matrices
Mar 10, 2025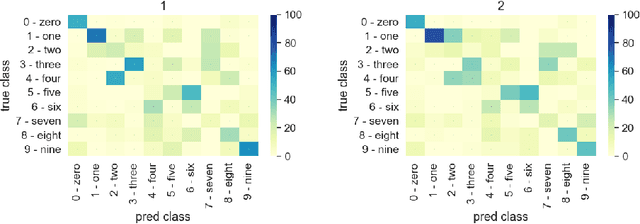

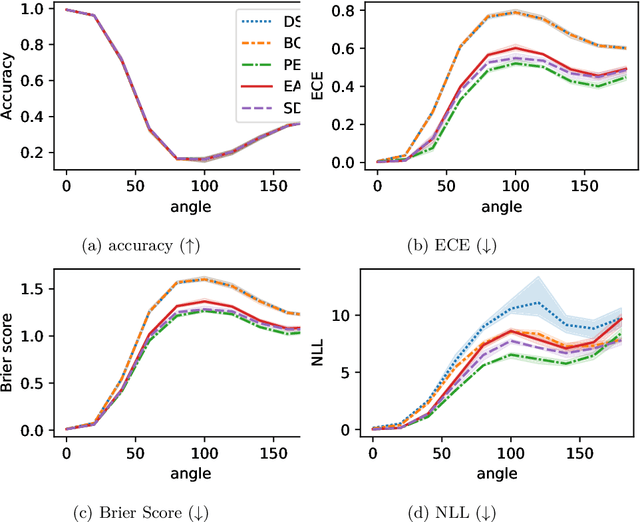

Ensembling in deep learning improves accuracy and calibration over single networks. The traditional aggregation approach, ensemble averaging, treats all individual networks equally by averaging their outputs. Inspired by crowdsourcing we propose an aggregation method called soft Dawid Skene for deep ensembles that estimates confusion matrices of ensemble members and weighs them according to their inferred performance. Soft Dawid Skene aggregates soft labels in contrast to hard labels often used in crowdsourcing. We empirically show the superiority of soft Dawid Skene in accuracy, calibration and out of distribution detection in comparison to ensemble averaging in extensive experiments.
Assessing the Potential of AI for Spatially Sensitive Nature-Related Financial Risks
Apr 26, 2024There is growing recognition among financial institutions, financial regulators and policy makers of the importance of addressing nature-related risks and opportunities. Evaluating and assessing nature-related risks for financial institutions is challenging due to the large volume of heterogeneous data available on nature and the complexity of investment value chains and the various components' relationship to nature. The dual problem of scaling data analytics and analysing complex systems can be addressed using Artificial Intelligence (AI). We address issues such as plugging existing data gaps with discovered data, data estimation under uncertainty, time series analysis and (near) real-time updates. This report presents potential AI solutions for models of two distinct use cases, the Brazil Beef Supply Use Case and the Water Utility Use Case. Our two use cases cover a broad perspective within sustainable finance. The Brazilian cattle farming use case is an example of greening finance - integrating nature-related considerations into mainstream financial decision-making to transition investments away from sectors with poor historical track records and unsustainable operations. The deployment of nature-based solutions in the UK water utility use case is an example of financing green - driving investment to nature-positive outcomes. The two use cases also cover different sectors, geographies, financial assets and AI modelling techniques, providing an overview on how AI could be applied to different challenges relating to nature's integration into finance. This report is primarily aimed at financial institutions but is also of interest to ESG data providers, TNFD, systems modellers, and, of course, AI practitioners.
Disaster mapping from satellites: damage detection with crowdsourced point labels
Nov 05, 2021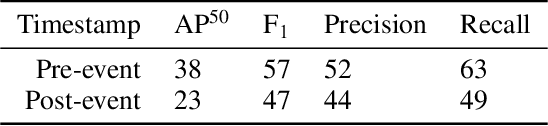


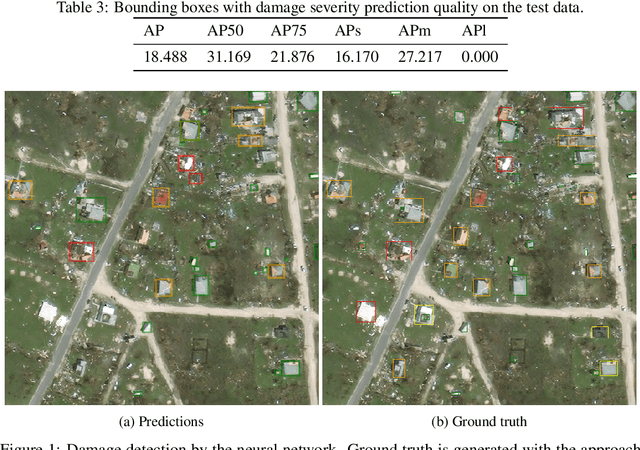
High-resolution satellite imagery available immediately after disaster events is crucial for response planning as it facilitates broad situational awareness of critical infrastructure status such as building damage, flooding, and obstructions to access routes. Damage mapping at this scale would require hundreds of expert person-hours. However, a combination of crowdsourcing and recent advances in deep learning reduces the effort needed to just a few hours in real time. Asking volunteers to place point marks, as opposed to shapes of actual damaged areas, significantly decreases the required analysis time for response during the disaster. However, different volunteers may be inconsistent in their marking. This work presents methods for aggregating potentially inconsistent damage marks to train a neural network damage detector.
Mining and Tailings Dam Detection In Satellite Imagery Using Deep Learning
Jul 02, 2020
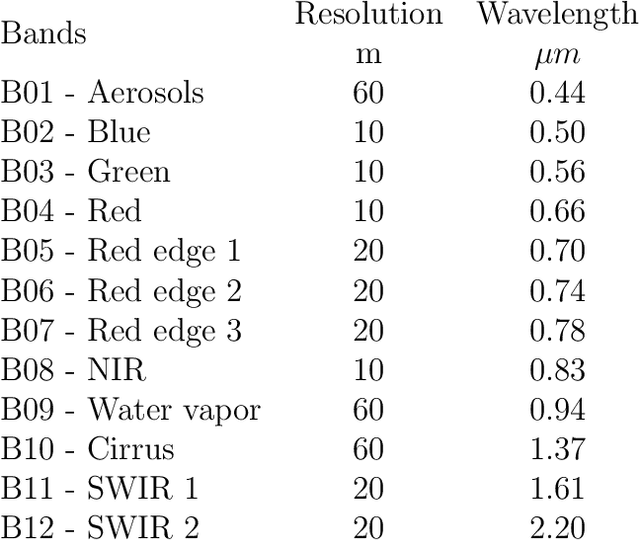
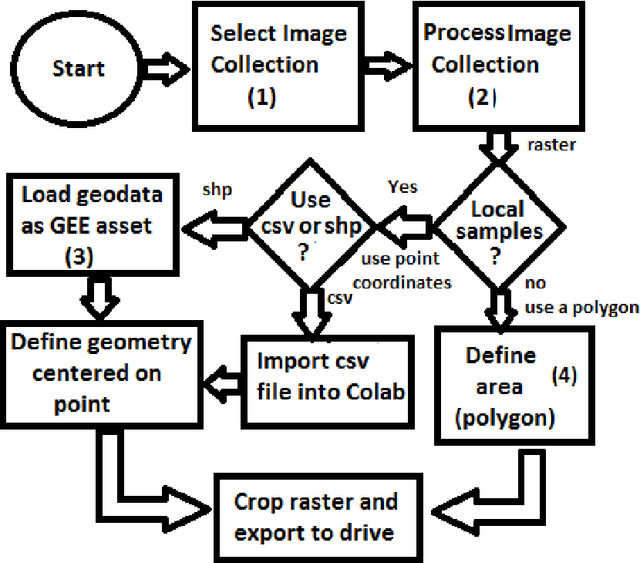
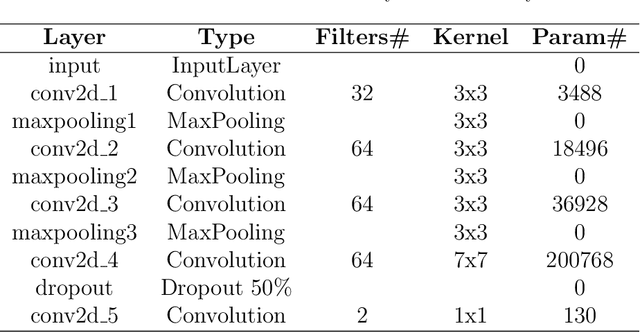
This work explores the combination of free cloud computing, free open-source software, and deep learning methods to analyse a real, large-scale problem: the automatic country-wide identification and classification of surface mines and mining tailings dams in Brazil. Locations of officially registered mines and dams were obtained from the Brazilian government open data resource. Multispectral Sentinel-2 satellite imagery, obtained and processed at the Google Earth Engine platform, was used to train and test deep neural networks using the TensorFlow 2 API and Google Colab platform. Fully Convolutional Neural Networks were used in an innovative way, to search for unregistered ore mines and tailing dams in large areas of the Brazilian territory. The efficacy of the approach is demonstrated by the discovery of 263 mines that do not have an official mining concession. This exploratory work highlights the potential of a set of new technologies, freely available, for the construction of low cost data science tools that have high social impact. At the same time, it discusses and seeks to suggest practical solutions for the complex and serious problem of illegal mining and the proliferation of tailings dams, which pose high risks to the population and the environment, especially in developing countries. Code is made publicly available at: https://github.com/remis/mining-discovery-with-deep-learning.
Bayesian Heatmaps: Probabilistic Classification with Multiple Unreliable Information Sources
Apr 05, 2019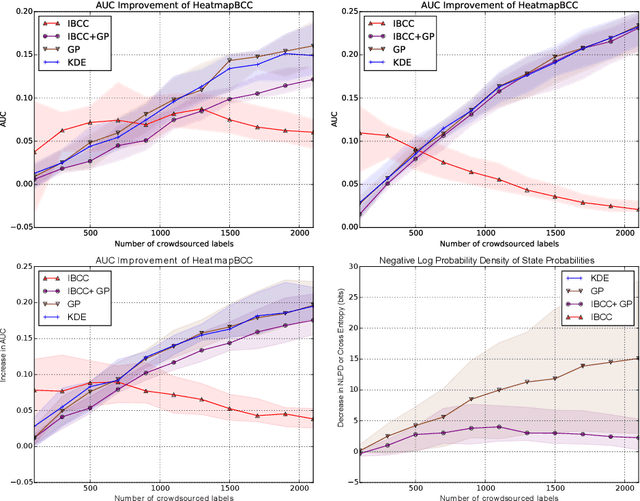

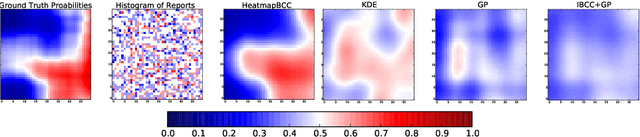
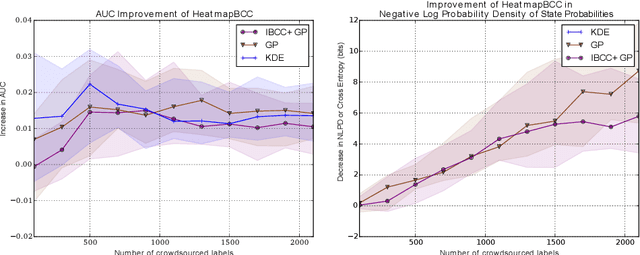
Unstructured data from diverse sources, such as social media and aerial imagery, can provide valuable up-to-date information for intelligent situation assessment. Mining these different information sources could bring major benefits to applications such as situation awareness in disaster zones and mapping the spread of diseases. Such applications depend on classifying the situation across a region of interest, which can be depicted as a spatial "heatmap". Annotating unstructured data using crowdsourcing or automated classifiers produces individual classifications at sparse locations that typically contain many errors. We propose a novel Bayesian approach that models the relevance, error rates and bias of each information source, enabling us to learn a spatial Gaussian Process classifier by aggregating data from multiple sources with varying reliability and relevance. Our method does not require gold-labelled data and can make predictions at any location in an area of interest given only sparse observations. We show empirically that our approach can handle noisy and biased data sources, and that simultaneously inferring reliability and transferring information between neighbouring reports leads to more accurate predictions. We demonstrate our method on two real-world problems from disaster response, showing how our approach reduces the amount of crowdsourced data required and can be used to generate valuable heatmap visualisations from SMS messages and satellite images.
BCCNet: Bayesian classifier combination neural network
Nov 29, 2018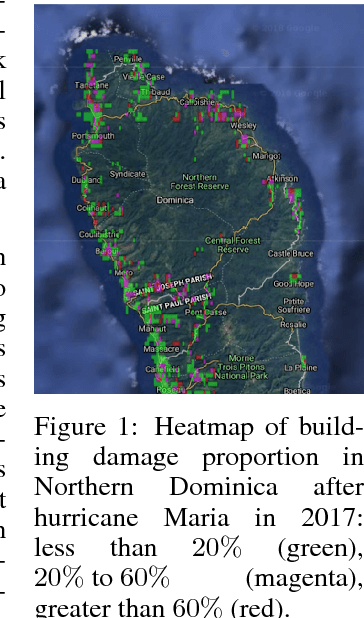
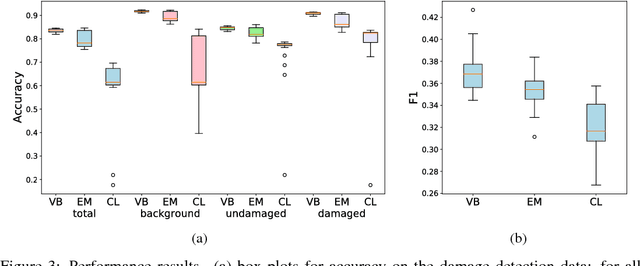
Machine learning research for developing countries can demonstrate clear sustainable impact by delivering actionable and timely information to in-country government organisations (GOs) and NGOs in response to their critical information requirements. We co-create products with UK and in-country commercial, GO and NGO partners to ensure the machine learning algorithms address appropriate user needs whether for tactical decision making or evidence-based policy decisions. In one particular case, we developed and deployed a novel algorithm, BCCNet, to quickly process large quantities of unstructured data to prevent and respond to natural disasters. Crowdsourcing provides an efficient mechanism to generate labels from unstructured data to prime machine learning algorithms for large scale data analysis. However, these labels are often imperfect with qualities varying among different citizen scientists, which prohibits their direct use with many state-of-the-art machine learning techniques. We describe BCCNet, a framework that simultaneously aggregates biased and contradictory labels from the crowd and trains an automatic classifier to process new data. Our case studies, mosquito sound detection for malaria prevention and damage detection for disaster response, show the efficacy of our method in the challenging context of developing world applications.
Anomaly Detection and Removal Using Non-Stationary Gaussian Processes
Jul 02, 2015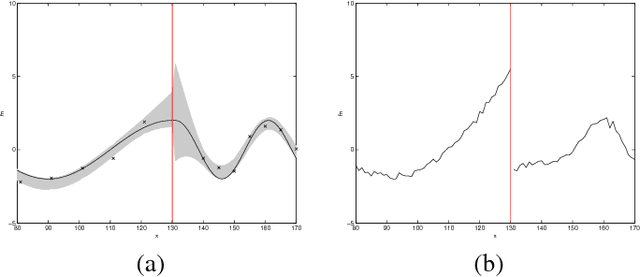

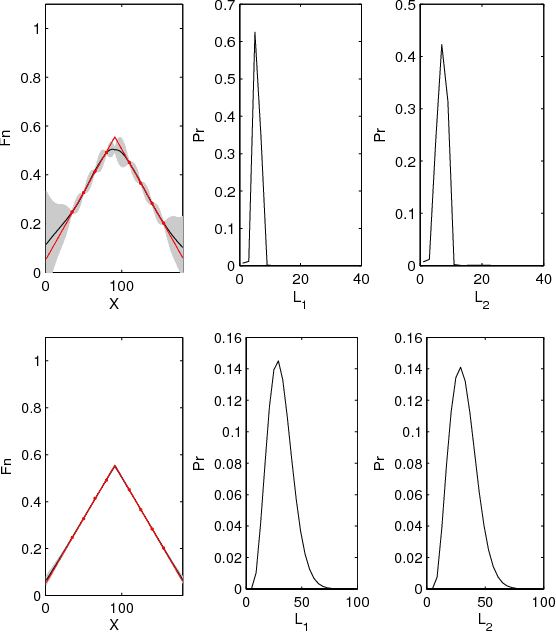
This paper proposes a novel Gaussian process approach to fault removal in time-series data. Fault removal does not delete the faulty signal data but, instead, massages the fault from the data. We assume that only one fault occurs at any one time and model the signal by two separate non-parametric Gaussian process models for both the physical phenomenon and the fault. In order to facilitate fault removal we introduce the Markov Region Link kernel for handling non-stationary Gaussian processes. This kernel is piece-wise stationary but guarantees that functions generated by it and their derivatives (when required) are everywhere continuous. We apply this kernel to the removal of drift and bias errors in faulty sensor data and also to the recovery of EOG artifact corrupted EEG signals.
Automated Machine Learning on Big Data using Stochastic Algorithm Tuning
Jul 30, 2014
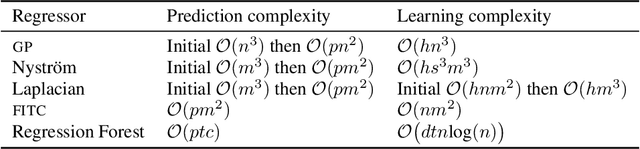
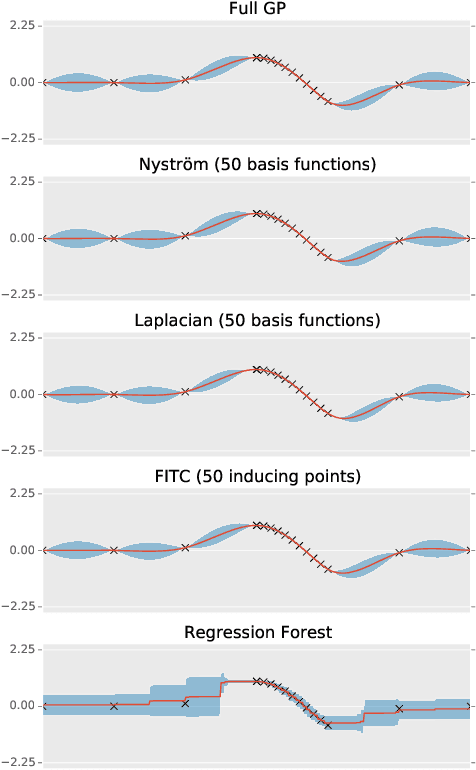

We introduce a means of automating machine learning (ML) for big data tasks, by performing scalable stochastic Bayesian optimisation of ML algorithm parameters and hyper-parameters. More often than not, the critical tuning of ML algorithm parameters has relied on domain expertise from experts, along with laborious hand-tuning, brute search or lengthy sampling runs. Against this background, Bayesian optimisation is finding increasing use in automating parameter tuning, making ML algorithms accessible even to non-experts. However, the state of the art in Bayesian optimisation is incapable of scaling to the large number of evaluations of algorithm performance required to fit realistic models to complex, big data. We here describe a stochastic, sparse, Bayesian optimisation strategy to solve this problem, using many thousands of noisy evaluations of algorithm performance on subsets of data in order to effectively train algorithms for big data. We provide a comprehensive benchmarking of possible sparsification strategies for Bayesian optimisation, concluding that a Nystrom approximation offers the best scaling and performance for real tasks. Our proposed algorithm demonstrates substantial improvement over the state of the art in tuning the parameters of a Gaussian Process time series prediction task on real, big data.
Efficient State-Space Inference of Periodic Latent Force Models
May 29, 2014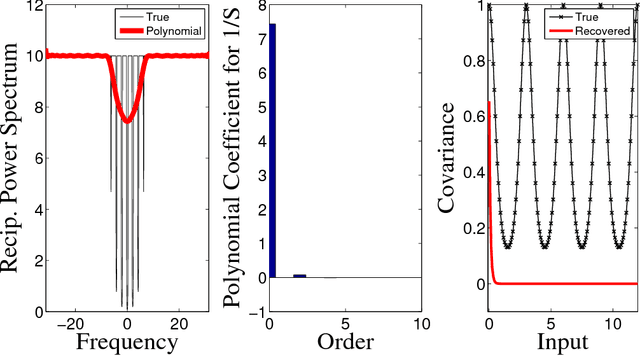

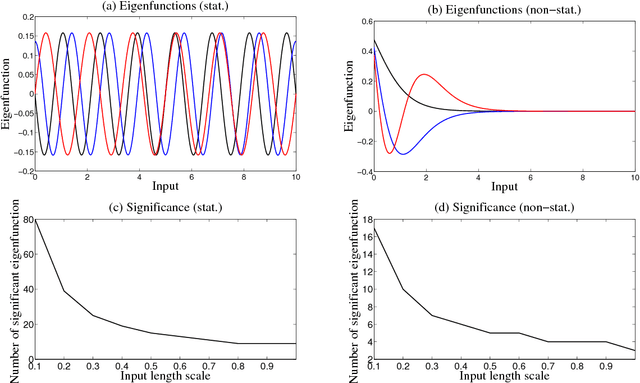
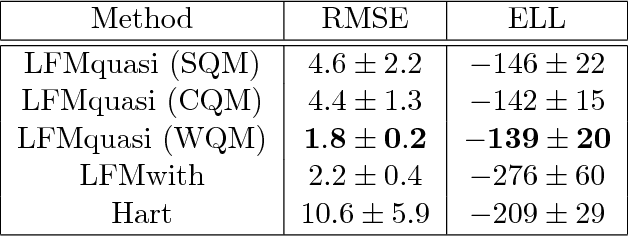
Latent force models (LFM) are principled approaches to incorporating solutions to differential equations within non-parametric inference methods. Unfortunately, the development and application of LFMs can be inhibited by their computational cost, especially when closed-form solutions for the LFM are unavailable, as is the case in many real world problems where these latent forces exhibit periodic behaviour. Given this, we develop a new sparse representation of LFMs which considerably improves their computational efficiency, as well as broadening their applicability, in a principled way, to domains with periodic or near periodic latent forces. Our approach uses a linear basis model to approximate one generative model for each periodic force. We assume that the latent forces are generated from Gaussian process priors and develop a linear basis model which fully expresses these priors. We apply our approach to model the thermal dynamics of domestic buildings and show that it is effective at predicting day-ahead temperatures within the homes. We also apply our approach within queueing theory in which quasi-periodic arrival rates are modelled as latent forces. In both cases, we demonstrate that our approach can be implemented efficiently using state-space methods which encode the linear dynamic systems via LFMs. Further, we show that state estimates obtained using periodic latent force models can reduce the root mean squared error to 17% of that from non-periodic models and 27% of the nearest rival approach which is the resonator model.