 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlitzkriging: Kronecker-structured Stochastic Gaussian Processes
Oct 31, 2015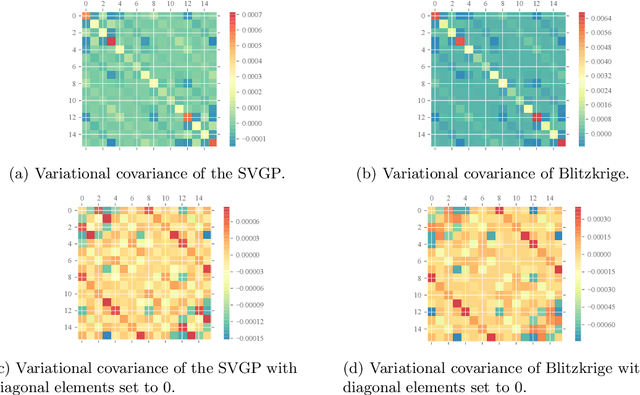

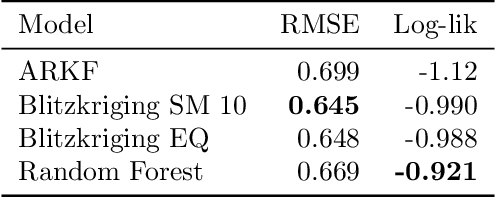
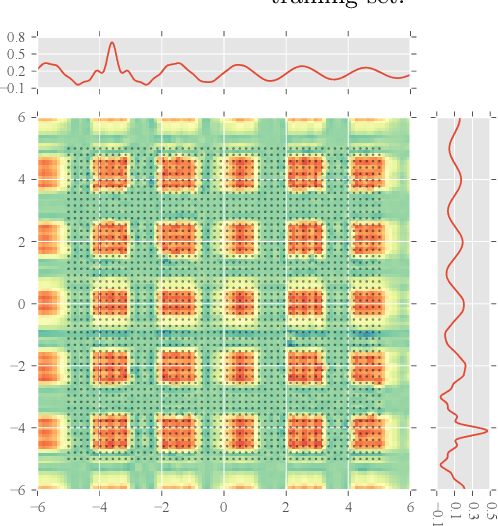
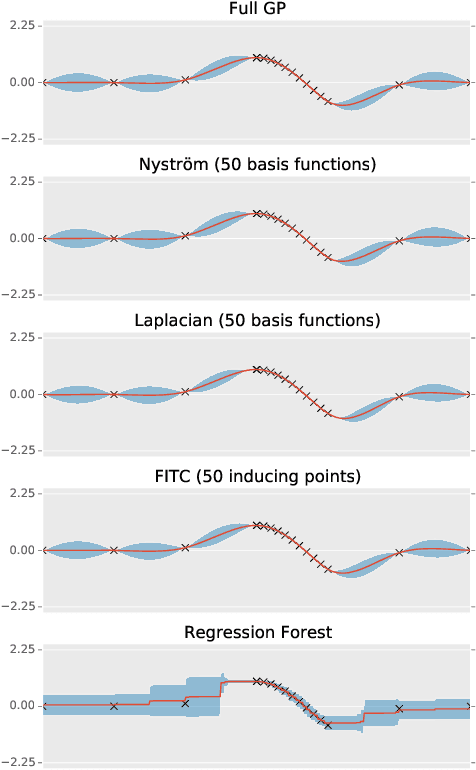
We present Blitzkriging, a new approach to fast inference for Gaussian processes, applicable to regression, optimisation and classification. State-of-the-art (stochastic) inference for Gaussian processes on very large datasets scales cubically in the number of 'inducing inputs', variables introduced to factorise the model. Blitzkriging shares state-of-the-art scaling with data, but reduces the scaling in the number of inducing points to approximately linear. Further, in contrast to other methods, Blitzkriging: does not force the data to conform to any particular structure (including grid-like); reduces reliance on error-prone optimisation of inducing point locations; and is able to learn rich (covariance) structure from the data. We demonstrate the benefits of our approach on real data in regression, time-series prediction and signal-interpolation experiments.
Automated Machine Learning on Big Data using Stochastic Algorithm Tuning
Jul 30, 2014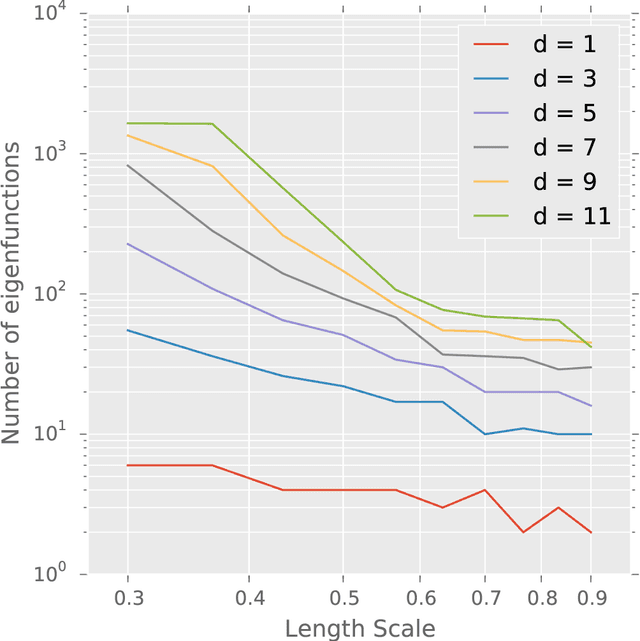
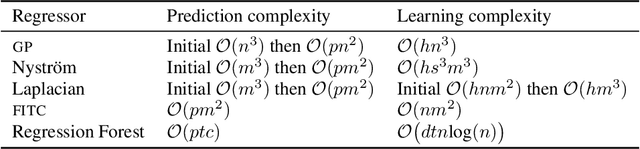

We introduce a means of automating machine learning (ML) for big data tasks, by performing scalable stochastic Bayesian optimisation of ML algorithm parameters and hyper-parameters. More often than not, the critical tuning of ML algorithm parameters has relied on domain expertise from experts, along with laborious hand-tuning, brute search or lengthy sampling runs. Against this background, Bayesian optimisation is finding increasing use in automating parameter tuning, making ML algorithms accessible even to non-experts. However, the state of the art in Bayesian optimisation is incapable of scaling to the large number of evaluations of algorithm performance required to fit realistic models to complex, big data. We here describe a stochastic, sparse, Bayesian optimisation strategy to solve this problem, using many thousands of noisy evaluations of algorithm performance on subsets of data in order to effectively train algorithms for big data. We provide a comprehensive benchmarking of possible sparsification strategies for Bayesian optimisation, concluding that a Nystrom approximation offers the best scaling and performance for real tasks. Our proposed algorithm demonstrates substantial improvement over the state of the art in tuning the parameters of a Gaussian Process time series prediction task on real, big data.