 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Accuracy: EcoL2 Metric for Sustainable Neural PDE Solvers
May 18, 2025Real-world systems, from aerospace to railway engineering, are modeled with partial differential equations (PDEs) describing the physics of the system. Estimating robust solutions for such problems is essential. Deep learning-based architectures, such as neural PDE solvers, have recently gained traction as a reliable solution method. The current state of development of these approaches, however, primarily focuses on improving accuracy. The environmental impact of excessive computation, leading to increased carbon emissions, has largely been overlooked. This paper introduces a carbon emission measure for a range of PDE solvers. Our proposed metric, EcoL2, balances model accuracy with emissions across data collection, model training, and deployment. Experiments across both physics-informed machine learning and operator learning architectures demonstrate that the proposed metric presents a holistic assessment of model performance and emission cost. As such solvers grow in scale and deployment, EcoL2 represents a step toward building performant scientific machine learning systems with lower long-term environmental impact.
Zero-shot and few-shot time series forecasting with ordinal regression recurrent neural networks
Mar 26, 2020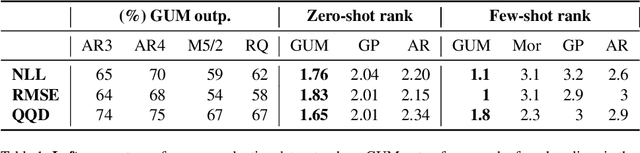
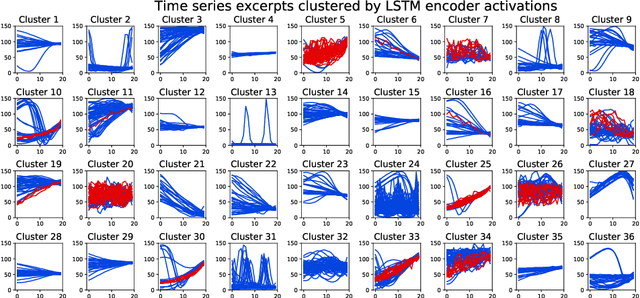
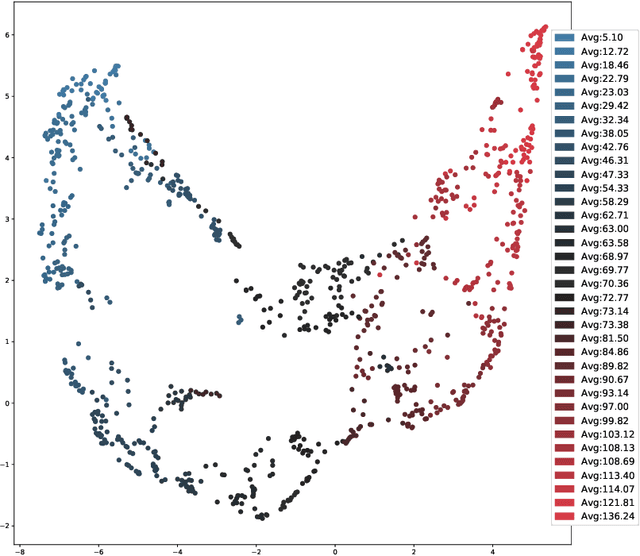
Recurrent neural networks (RNNs) are state-of-the-art in several sequential learning tasks, but they often require considerable amounts of data to generalise well. For many time series forecasting (TSF) tasks, only a few dozens of observations may be available at training time, which restricts use of this class of models. We propose a novel RNN-based model that directly addresses this problem by learning a shared feature embedding over the space of many quantised time series. We show how this enables our RNN framework to accurately and reliably forecast unseen time series, even when there is little to no training data available.
Implicit Priors for Knowledge Sharing in Bayesian Neural Networks
Dec 02, 2019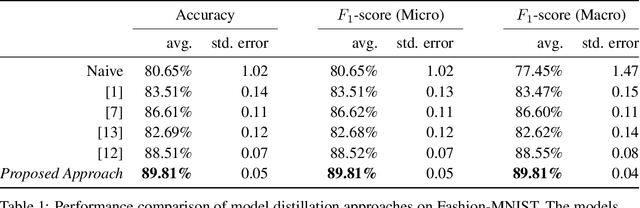
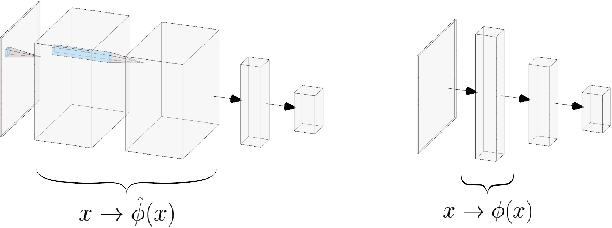

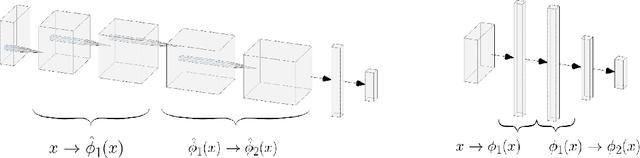
Bayesian interpretations of neural network have a long history, dating back to early work in the 1990's and have recently regained attention because of their desirable properties like uncertainty estimation, model robustness and regularisation. We want to discuss here the application of Bayesian models to knowledge sharing between neural networks. Knowledge sharing comes in different facets, such as transfer learning, model distillation and shared embeddings. All of these tasks have in common that learned "features" ought to be shared across different networks. Theoretically rooted in the concepts of Bayesian neural networks this work has widespread application to general deep learning.
* 5 pages, 2 figures
Bayesian Optimisation over Multiple Continuous and Categorical Inputs
Jun 20, 2019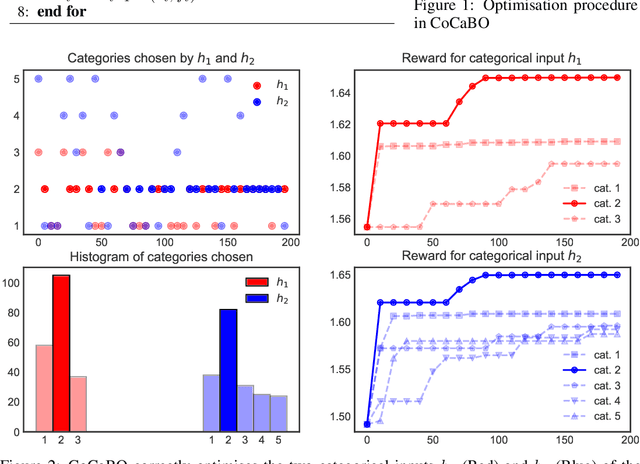

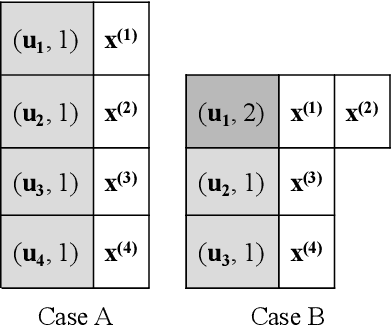

Efficient optimisation of black-box problems that comprise both continuous and categorical inputs is important, yet poses significant challenges. We propose a new approach, Continuous and Categorical Bayesian Optimisation (CoCaBO), which combines the strengths of multi-armed bandits and Bayesian optimisation to select values for both categorical and continuous inputs. We model this mixed-type space using a Gaussian Process kernel, designed to allow sharing of information across multiple categorical variables, each with multiple possible values; this allows CoCaBO to leverage all available data efficiently. We extend our method to the batch setting and propose an efficient selection procedure that dynamically balances exploration and exploitation whilst encouraging batch diversity. We demonstrate empirically that our method outperforms existing approaches on both synthetic and real-world optimisation tasks with continuous and categorical inputs.
Semi-Unsupervised Learning with Deep Generative Models: Clustering and Classifying using Ultra-Sparse Labels
Jan 24, 2019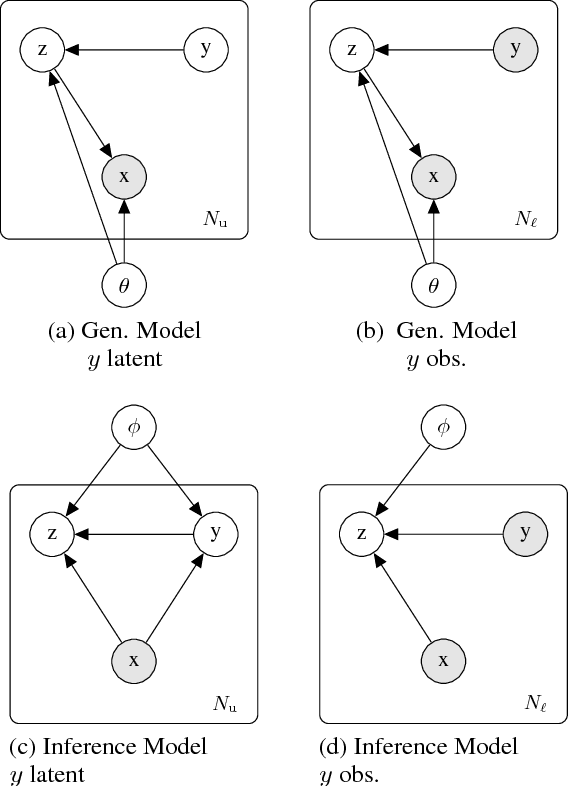
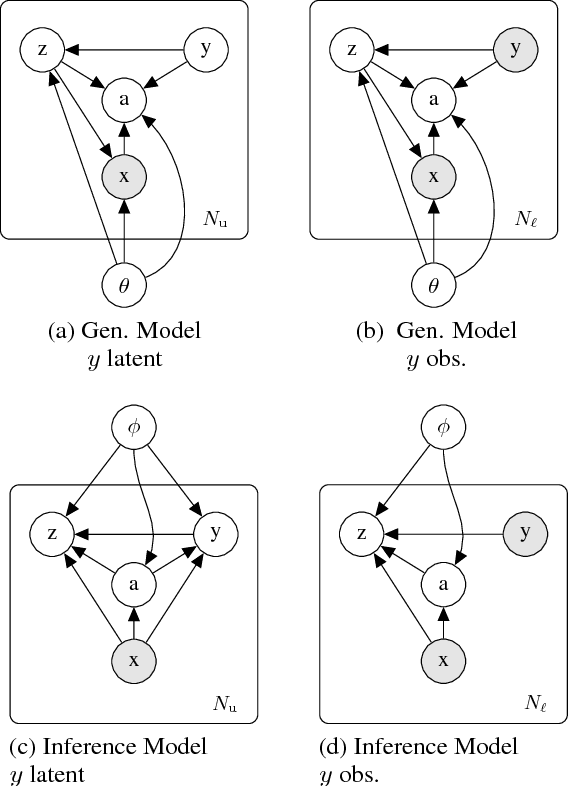
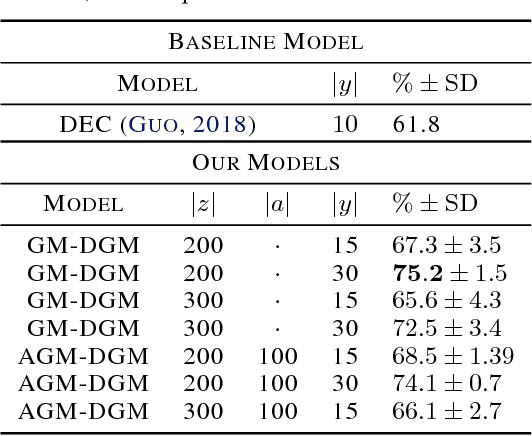
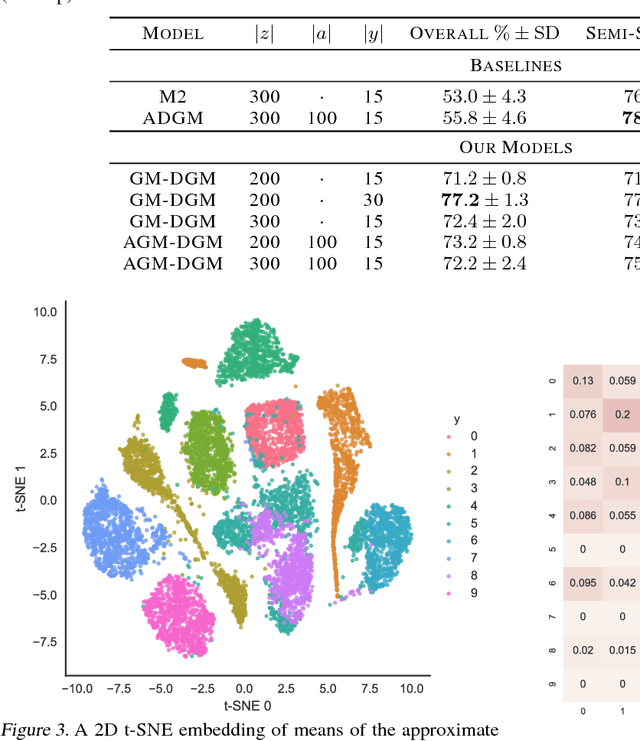
We introduce $\textit{semi-unsupervised learning}$, an extreme case of semi-supervised learning with ultra-sparse categorisation where some classes have no labels in the training set. That is, in the training data some classes are sparsely labelled and other classes appear only as unlabelled data. Many real-world datasets are conceivably of this type. We demonstrate that effective learning in this regime is only possible when a model is capable of capturing both semi-supervised and unsupervised learning. We develop two deep generative models for classification in this regime that extend previous deep generative models designed for semi-supervised learning. By changing their probabilistic structure to contain a mixture of Gaussians in their continuous latent space, these new models can learn in both unsupervised and semi-unsupervised paradigms. We demonstrate their performance both for semi-unsupervised and unsupervised learning on various standard datasets. We show that our models can learn in an semi-unsupervised manner on Fashion-MNIST. Here we artificially mask out all labels for half of the classes of data and keep $2\%$ of labels for the remaining classes. Our model is able to learn effectively, obtaining a trained classifier with $(77.2\pm1.3)\%$ test set accuracy. We also can train on Fashion-MNIST unsupervised, obtaining $(75.2\pm1.5)\%$ test set accuracy. Additionally, doing the same for MNIST unsupervised we get $(96.3\pm0.9)\%$ test set accuracy, which is state-of-the art for fully probabilistic deep generative models.
BCCNet: Bayesian classifier combination neural network
Nov 29, 2018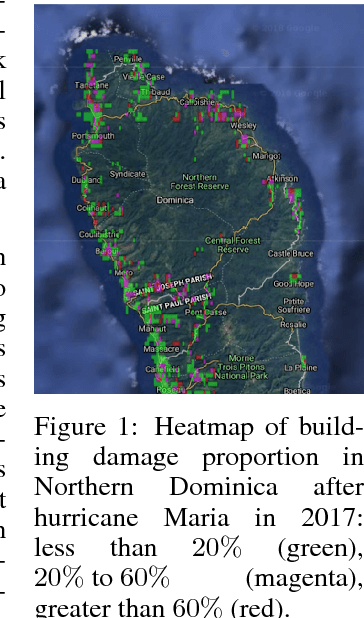
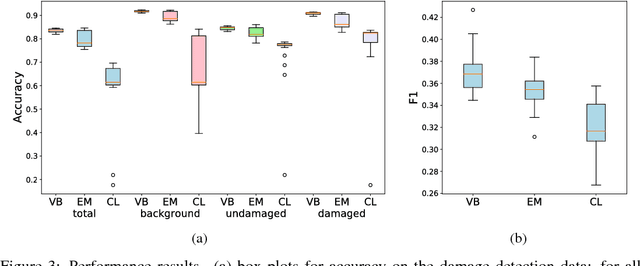
Machine learning research for developing countries can demonstrate clear sustainable impact by delivering actionable and timely information to in-country government organisations (GOs) and NGOs in response to their critical information requirements. We co-create products with UK and in-country commercial, GO and NGO partners to ensure the machine learning algorithms address appropriate user needs whether for tactical decision making or evidence-based policy decisions. In one particular case, we developed and deployed a novel algorithm, BCCNet, to quickly process large quantities of unstructured data to prevent and respond to natural disasters. Crowdsourcing provides an efficient mechanism to generate labels from unstructured data to prime machine learning algorithms for large scale data analysis. However, these labels are often imperfect with qualities varying among different citizen scientists, which prohibits their direct use with many state-of-the-art machine learning techniques. We describe BCCNet, a framework that simultaneously aggregates biased and contradictory labels from the crowd and trains an automatic classifier to process new data. Our case studies, mosquito sound detection for malaria prevention and damage detection for disaster response, show the efficacy of our method in the challenging context of developing world applications.
Automated Machine Learning on Big Data using Stochastic Algorithm Tuning
Jul 30, 2014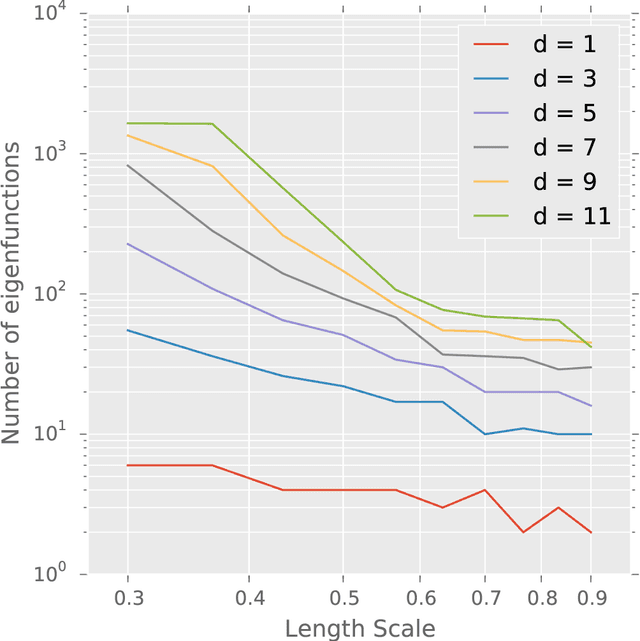
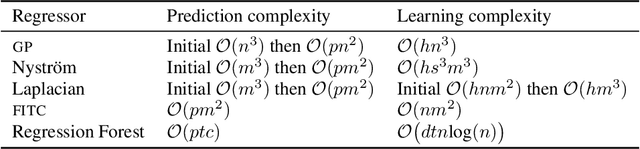
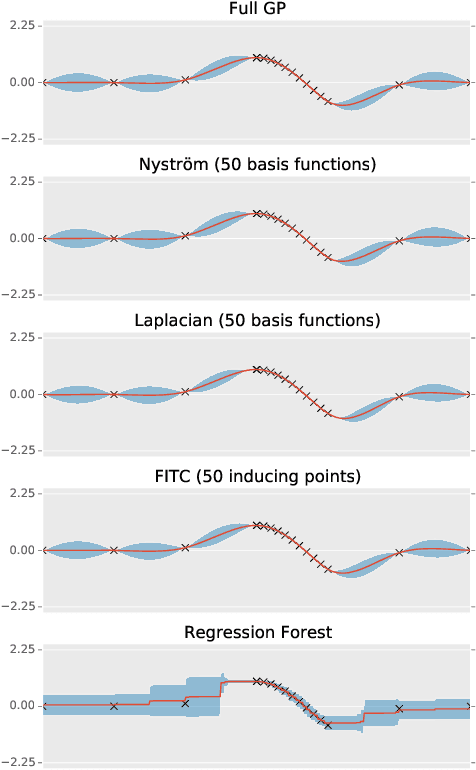

We introduce a means of automating machine learning (ML) for big data tasks, by performing scalable stochastic Bayesian optimisation of ML algorithm parameters and hyper-parameters. More often than not, the critical tuning of ML algorithm parameters has relied on domain expertise from experts, along with laborious hand-tuning, brute search or lengthy sampling runs. Against this background, Bayesian optimisation is finding increasing use in automating parameter tuning, making ML algorithms accessible even to non-experts. However, the state of the art in Bayesian optimisation is incapable of scaling to the large number of evaluations of algorithm performance required to fit realistic models to complex, big data. We here describe a stochastic, sparse, Bayesian optimisation strategy to solve this problem, using many thousands of noisy evaluations of algorithm performance on subsets of data in order to effectively train algorithms for big data. We provide a comprehensive benchmarking of possible sparsification strategies for Bayesian optimisation, concluding that a Nystrom approximation offers the best scaling and performance for real tasks. Our proposed algorithm demonstrates substantial improvement over the state of the art in tuning the parameters of a Gaussian Process time series prediction task on real, big data.