 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Speech Summarisation: A Scoping Review
Aug 27, 2020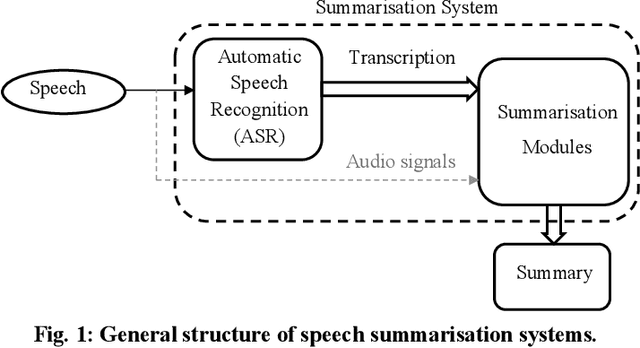
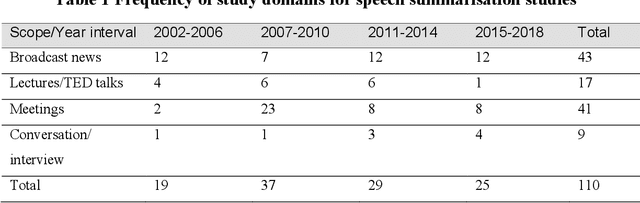
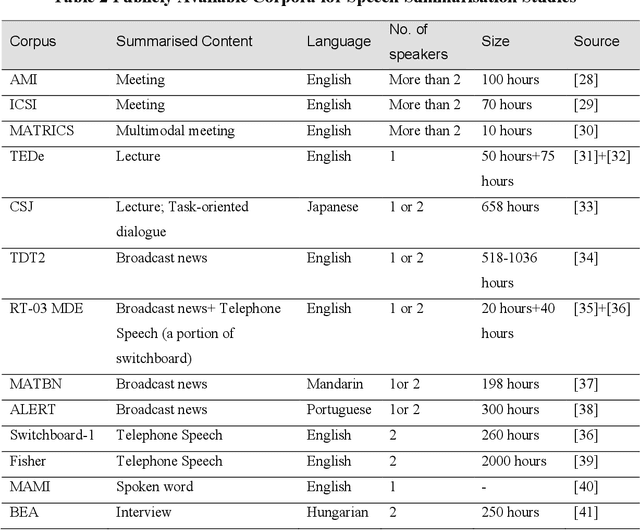
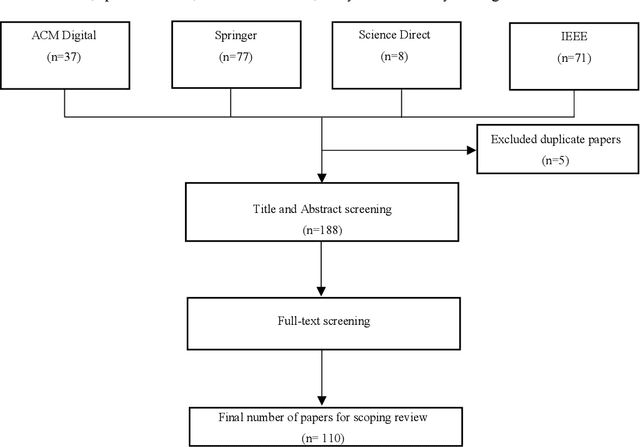
Speech summarisation techniques take human speech as input and then output an abridged version as text or speech. Speech summarisation has applications in many domains from information technology to health care, for example improving speech archives or reducing clinical documentation burden. This scoping review maps the speech summarisation literature, with no restrictions on time frame, language summarised, research method, or paper type. We reviewed a total of 110 papers out of a set of 153 found through a literature search and extracted speech features used, methods, scope, and training corpora. Most studies employ one of four speech summarisation architectures: (1) Sentence extraction and compaction; (2) Feature extraction and classification or rank-based sentence selection; (3) Sentence compression and compression summarisation; and (4) Language modelling. We also discuss the strengths and weaknesses of these different methods and speech features. Overall, supervised methods (e.g. Hidden Markov support vector machines, Ranking support vector machines, Conditional random fields) performed better than unsupervised methods. As supervised methods require manually annotated training data which can be costly, there was more interest in unsupervised methods. Recent research into unsupervised methods focusses on extending language modelling, for example by combining Uni-gram modelling with deep neural networks. Protocol registration: The protocol for this scoping review is registered at https://osf.io.
Empirical Analysis of Zipf's Law, Power Law, and Lognormal Distributions in Medical Discharge Reports
Mar 30, 2020
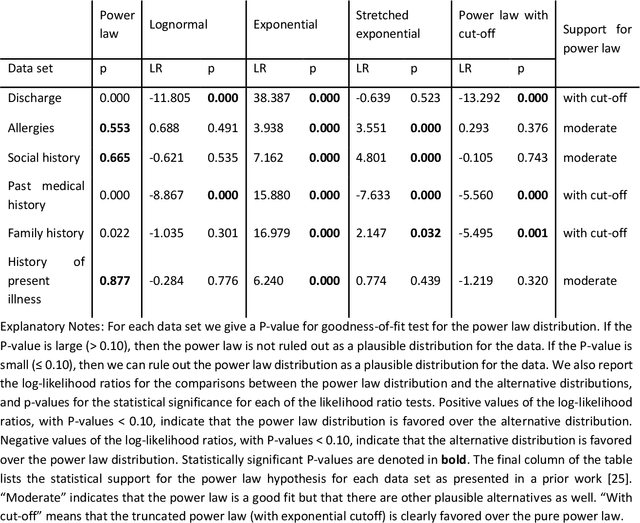
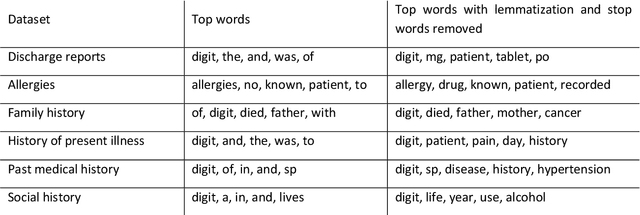
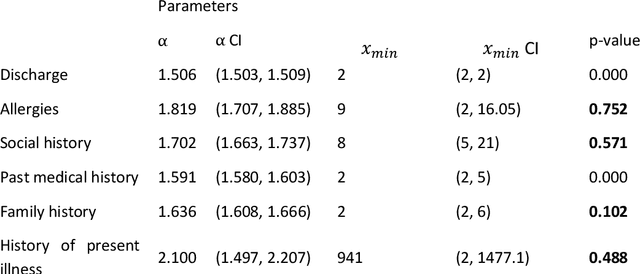
Bayesian modelling and statistical text analysis rely on informed probability priors to encourage good solutions. This paper empirically analyses whether text in medical discharge reports follow Zipf's law, a commonly assumed statistical property of language where word frequency follows a discrete power law distribution. We examined 20,000 medical discharge reports from the MIMIC-III dataset. Methods included splitting the discharge reports into tokens, counting token frequency, fitting power law distributions to the data, and testing whether alternative distributions--lognormal, exponential, stretched exponential, and truncated power law--provided superior fits to the data. Results show that discharge reports are best fit by the truncated power law and lognormal distributions. Our findings suggest that Bayesian modelling and statistical text analysis of discharge report text would benefit from using truncated power law and lognormal probability priors.